案例:Fama-French三因子模型的应用
自20世纪70年代以来,实证资定价研究已经走过了近50年的发展。从CAPM到如今家喻户晓的Fama-French和q-factor 等因子模型。从“Factor Zoo”再到“Factor War”,资产定价领域已经拥有了浩如烟海的多因子建模学术文献。
1. 问题定义¶
在多因子模型被提出之前,CAPM是资产定价的第一范式。
1.1 CAPM模型¶
CAPM模型是资本资产定价模型(Capital Asset Pricing Model)的缩写。这个模型用来估计资产的预期回报率,基于资产的风险水平。这个模型假设了资产回报率的线性关系,其中风险被定义为资产的β系数(Beta)。CAPM模型的基本公式如下:
其中:
是资产i的预期回报率
是无风险利率
是市场的预期回报率
是资产i的贝塔系数(反映了该资产相对于市场的风险)
是市场超额回报率
CAPM模型认为,资产的预期回报率取决于其β系数和市场的预期回报率与无风险利率之间的差异。
然而,自20纪70年代以来,学者们逐渐发现按照某种风格"打包"的股票能够战胜市场。这其中最值得一提的是Basu(1977)发现的盈利市值比(EP)效应和Banz(1981)发现的小市值效应。继EP之后,账面市值比(BM)和债务市值比(debt to market value of equity, DM)效应也被发现。
虽然单一异象被发现后都对CAPM提出了挑战,但它们并没有形成合力,因此人们并未对CAPM产生太大的质疑,直到Fama and French(1992)横空出世,它整合了之前被提出的多种异象,彻底颠覆了人们对CAPM的看法。
当然,由于CAPM在数学上足够简单优雅,且在业务上非常容易解释(风险来自对市场的暴露),因此它还是资产定价的一个很好的出发点,只是人们再也无法忽视不能被CAPM解释的其他系统性风险因子了。
1.2 Fama-French三因子¶

图:Eugene Fama 和 Kenneth French,金融经济学领域的两位知名学者
Fama-French三因子模型是由经济学家Eugene Fama和Kenneth French提出的一种用于解释股票收益的资产定价模型。该模型基于CAPM(Capital Asset Pricing Model,资本资产定价模型)的基础上,引入了两个额外的因子:市值因子(市值-账面价值比,Mkt-RF)和账面市值比因子(SMB,Small Minus Big)。
Fama-French三因子模型的数学形式如下:
其中:
是股票 ( i ) 的期望收益率;
是无风险利率;
是市场组合的期望收益率;
是市值因子(Small Minus Big);
是账面市值比因子(High Minus Low);
是模型的参数;
是误差项。
Fama-French三因子模型认为,股票的期望收益率除了与市场组合的风险有关外,还与市值因子和账面市值比因子相关。市值因子衡量了市场上小市值股票和大市值股票之间的差异,账面市值比因子衡量了账面市值比高的股票和低的股票之间的差异。通过引入这两个额外的因子,Fama-French三因子模型更好地解释了股票收益的变动。
为构建价值和规模因子,Fama and French(1993)选择了 BM和市值两个公司指标并用它们进行了如图所示的23独立双重排序。在排序时,以纽约证券交易所(Ne York Stock Exchange,NYSE)(下面简称纽交所)中上市公司的市值中位数为界,把NYSE、纳斯达克(NASDAQ)以及美国证券交易所(American Stock Exchange,AMEX)的上市公司分成小市值(Small)和大市值(Big)两组。类似的,以 NYSE 中上市公司 BM 的30%和70%分位数为界,把这三大交易所的上市公司分成三组:BM 高于 70%分位数的为High 组、BM低于 30% 分位数的为Low 组、位于中间的为Middle组。通过以上划分后,按照市值和BM 各自所属的组别,所有股票被分到一共6(2x3=6)个组中,记为 S/H、S/M、S/L、B/H、B/M及B/L。将每组中的股票收益率按市值加权就得到六个投资组合。最终,Fama and French(1993)使用如下方法构建了规模和价值两个因子:
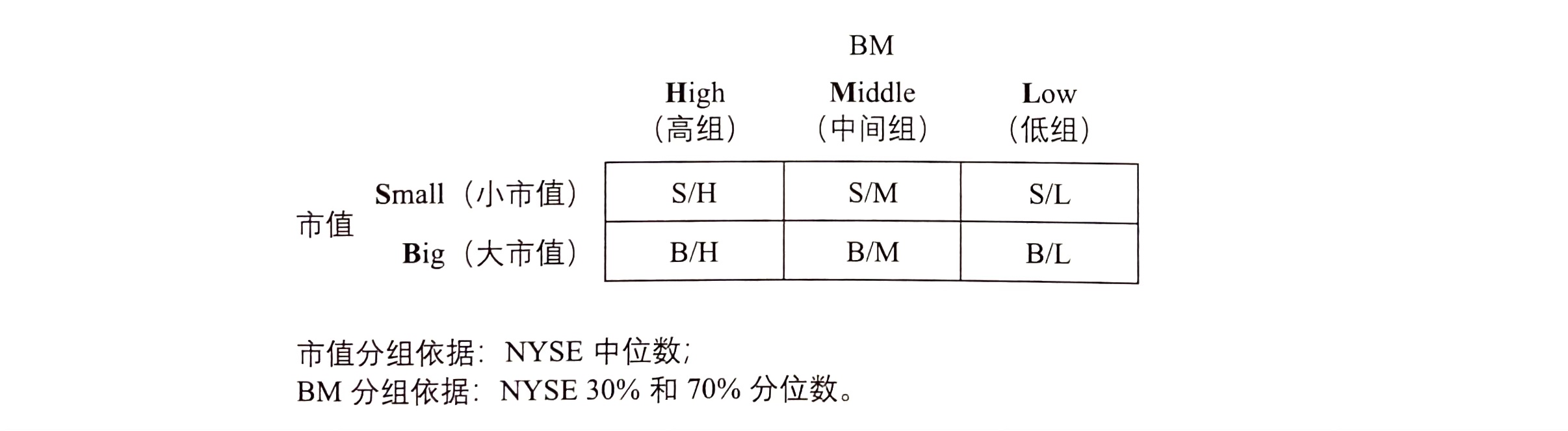
图1 BM和市值双重排序
不难看出,规模因子是三个小市值组合S/H、S/M及S/L的等权平均减去三个大市值组合B/H、B/M及B/L的等权平均;而价值因子是S/H和B/H两个高BM组合的两组合的等权平均。在每年的六月末,Fama and French(1993)使用上一财年最新的财务数据对股票重新排序并对这两个因子进行再平衡。Fama-French三因子模型被提出后逐步取代了CAPM成为资产定价的第一范式。而以上述双重划分以及以此衍生出来的多重划分来构建因子组合也成为学术界竞相模仿的对象。
表1 主流多因子模型
| 模型 | 出处 | 所含因子 |
|---|---|---|
| Fama - French 三因子 | Fama and French(1993) | 市场、规模、价值 |
| Carhart 四因子 | Carhart(1997) | 市场、规模、价值、动量 |
| Novy - Marx 四因子 | Novy-Marx(2013) | 市场、价值、动量、盈利 |
| Fama - French 五因子 | Fama and French(2015) | 市场、规模、价值、盈利、投资 |
| Hou - Xue - Zhang 四因子 | Hou et al.(2015) | 市场、规模、盈利、投资 |
| Stambaugh - Yuan 四因子 | Stambaugh and Yuan(2017) | 市场、规模、管理、表现 |
| Daniel - Hirshleifer - Sun 三因子 | Daniel et al.(2020) | 市场、长周期行为、短周期行为 |
作为第一个被提出的多因子模型,Fama-French三因子模型被反复进行检验。Daviset al.(2000)使用自1927年开始的数据模型;Fama and French(1998)使用其他国家的股票市场检验该模型;Fama and French(2008)使用三因子模型考察了那些无法被CAPM解释的异象。除此之外,Fama and French(1996)还尝试从风险的角度解释了SMB和HML两个因子,并猜想它们和上市公司的财务困境风险有关。
2. 载入数据¶
2.1 读取Fama-French三因子数据¶
Fama-French三因子数据来自于French在达特茅斯学院的MBA网站上。
import pandas as pd
df = pd.read_csv('datasets/F-F_Research_Data_Factors_weekly_CSV.csv', index_col=0)
df.head()df = df[['Mkt-RF', 'SMB', 'HML']]
name_dict = {'Mkt-RF':'Market Factor (MER)',
'SMB':'Size Factor (SMB)',
'HML':'Value Factor (HML)'}df.columns = [name_dict[i] for i in df.columns]
df.index = df.index.astype(str)
df.index = pd.to_datetime(df.index, format='%Y%m%d')df.head(5)2.2 读取资产数据¶
当我们研究投资组合,一个最佳的研究对象自然是股神巴菲特(Warren Buffett)。他在过去50年间实现了接近20%化收益。巴菲特师承价值投资的代表Benjamin Grahan(格雷厄姆),非常注重股票的购买价格(安全性)。与此同时,他也逐渐发展了自己的投资格,特别是对质量的高度重视。巴菲特是否真的具有这样的投资风格?经典的多因子是否可以很好地解释巴菲特的优异业绩?这些都是非常引人关注的问题。
这里我们选择其所管理的伯克希尔哈撒韦公司的股票数据,数据来源为investing.com,并选取其日收盘价。
import pandas as pd
BRK = pd.read_csv('datasets/BRKa历史数据.csv', index_col=0)
BRK = BRK.sort_index()
BRK.index = pd.to_datetime(BRK.index, format='%Y-%m-%d')
BRK.head()对数据的格式进行整理
import numpy as np
BRK['收盘'] = np.array([i.replace(',', '') for i in BRK['收盘']], dtype='float')BRK = BRK.sort_index()import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'Songti SC'
plt.rcParams['axes.unicode_minus'] = False
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
BRK['收盘'].plot(figsize=(10,4), title='伯克希尔哈撒韦公司的股价', color='green')<Axes: title={'center': '伯克希尔哈撒韦公司的股价'}, xlabel='日期'>period = 1
df['Return'] = BRK['收盘']/BRK['收盘'].shift(period) - 1
df['Return'] = df['Return'].ffill()
df = df[df.index>pd.to_datetime('2010-01-01')]
df['Return'].plot(figsize=(10,4), title='伯克希尔哈撒韦公司的股价', color='blue')<Axes: title={'center': '伯克希尔哈撒韦公司的股价'}, xlabel='Date'>fig, ax = plt.subplots(1,2, figsize=(10,4))
df['Return'].plot(ax=ax[0], kind='hist', bins=50, grid=False)
df['Return'].plot(ax=ax[1], kind='box', grid=False)<Axes: >剔除可能之后会影响回归模型的收益率极值
import numpy as np
QU = df['Return'].quantile(0.75)
QL = df['Return'].quantile(0.25)
IQR = QU - QL
df['Return'][(df['Return']>(QU + 1.5*IQR)) | (df['Return']<(QL-1.5*IQR))] = np.nan
df['Return'] = df['Return'].ffill()
fig, ax = plt.subplots(1,2, figsize=(10,4))
df['Return'].plot(ax=ax[0], kind='hist', bins=50, grid=False)
df['Return'].plot(ax=ax[1], kind='box', grid=False)<Axes: >3. 回归模型¶
我们使用seaborn来绘制变量和变量之间相关性的热力图,颜色为深色代表相关性越弱,颜色越浅代表相关性越强。接近红色,为正相关,接近蓝色,为负相关。
import seaborn as sns
plt.figure(figsize=(8,3))
sns.heatmap(df.corr(), annot = True, cmap='coolwarm')<Axes: >观察上面结果,部分解释变量和解释变量之间存在很高的相关性。
当然,我们可以绘制散点图观察解释变量和被解释变量之间的相关性,同时绘制一元回归的回归线。
fig, axs = plt.subplots(nrows=1, ncols=3, figsize=(12, 4))
for i, k in enumerate(['Market Factor (MER)', 'Size Factor (SMB)', 'Value Factor (HML)']):
sns.regplot(y=df['Return'], x=df[k], ax=axs[i])对于解释变量(自变量)X和被解释变量(因变量)y进行OLS回归:
import statsmodels.api as sm
df['Intercept'] = 1.
model=sm.OLS(df['Return'],
df[['Intercept', 'Market Factor (MER)', 'Size Factor (SMB)', 'Value Factor (HML)']])
result=model.fit()
result.summary(alpha=0.05)beta=pd.DataFrame([result.params[0:]],
columns=['Market Factor (MER)', 'Size Factor (SMB)', 'Value Factor (HML)'],
index=['coef'])
beta通过上述的分析,我们看到经典的三因子模型在每个因子上的风险暴露都是统计显著的,说明三个因子每个因子都能够解释一部分收益来源。但是模型整体的(0.114)比较低,说明三因子模型的解释力度不够,无法解释大部分收益来源。
练习¶
应用五因子模型对伯克希尔哈撒韦的股价进行回归,因子数据在datasets/F-F_Research_Data_5_Factors_daily.csv
参考¶
《因子投资:方法与实践》石川等, 2020
《高效的无效》Efficiently Inefficient, Lasse Heje Pedersen, 2021
Fama, E.F. and J. D. MacBeth (1973). Risk, return, and equilibrium: Empirical tests. Journal of Political Economy 81(3), 607-636.
《量化风险管理》Quantitative Risk Management,Alexander J.McNell, 2020
Multi-Factor models and Fama-French:coursera
FamaFrench in Github: https://
christianjauregui .github .io /famafrench /gettingstarted /gettingstarted .html ken.french数据库:http://
mba .tuck .dartmouth .edu /pages /faculty /ken .french /data _library .html Fama and French, 1993, “Common Risk Factors in the Returns on Stocks and Bonds,” Journal of Financial Economics