4.2 Pandas的数据框
Pandas的数据框(DataFrame)是一种二维的数据结构,类似于电子表格或关系型数据库中的表格。它由行和列组成,每列可以包含不同的数据类型(例如数字、字符串、布尔值等)。数据框是Pandas库中最常用的数据结构之一,它提供了许多功能强大的方法和工具,用于数据的处理、分析和操作。
1. 读取和创建数据框¶
数据框可以通过多种方式创建,例如从CSV文件、Excel文件、数据库查询结果等导入数据,或者通过手动创建一个字典、列表或NumPy数组来构建数据框。
从CSV文件导入数据,并创建数据框,方法如下:
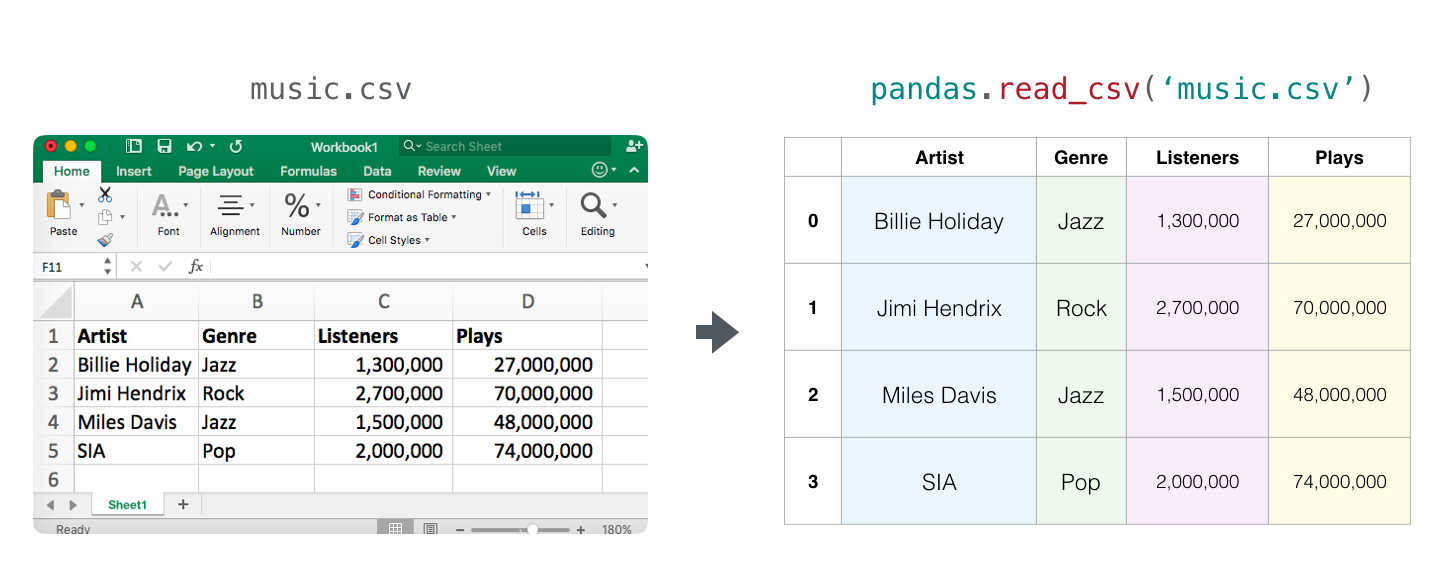
DataFrame的对象--基本上是一个数值表,每一行和每一列都有一个标签。上面的CSV文件来自一个音乐流媒体服务的数据,包含4个艺术家及其曲风、粉丝数、播放量这四列。
练习:加载CSV格式文件¶
使用pd.read_csv()加载路径下的CSV文件:‘datasets/music.csv’
如果通过创建字典的方式构建数据框,那么方法如下:
import pandas as pd
df = pd.DataFrame({'Artist':['Billie Holiday','Jimi Hendrix', 'Miles Davis', 'SIA'],
'Genre': ['Jazz', 'Rock', 'Jazz', 'Pop'],
'Listeners': [1300000, 2700000, 1500000, 2000000],
'Plays': [27000000, 70000000, 48000000, 74000000]})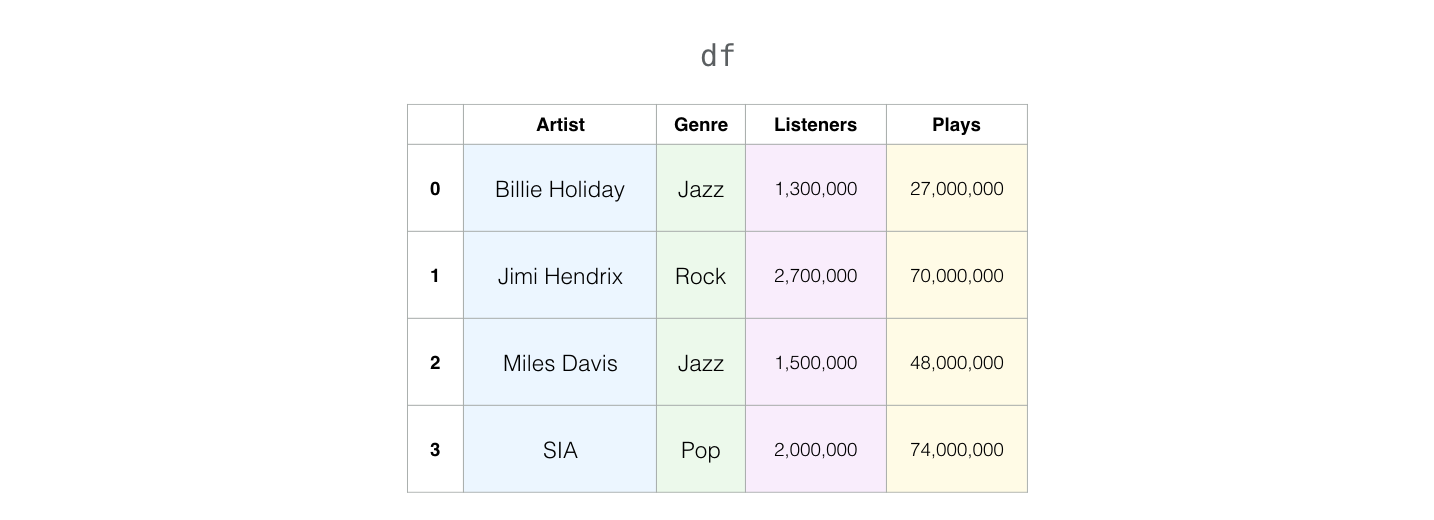
一旦创建了数据框,就可以使用Pandas提供的各种方法和函数来对数据进行筛选、排序、聚合、合并等操作,以满足不同的数据分析需求。
2. 选择¶
可以使用数据框的列名来选择特定的列数据。例如,使用df[‘Artists’]可以选择名为"Artists"的列数据。

当然可以使用行索引来选择特定的行数据。例如,使用df.loc[row_index]可以选择名为"row_index"的行数据。
当然也可以使用.loc来选择表格的任何片断(但这里会包括两个边界行号):

练习:选择部分区域元素¶
选择第1和第2行,列名为 “Artist” and "Plays"的部分。
3. 过滤¶
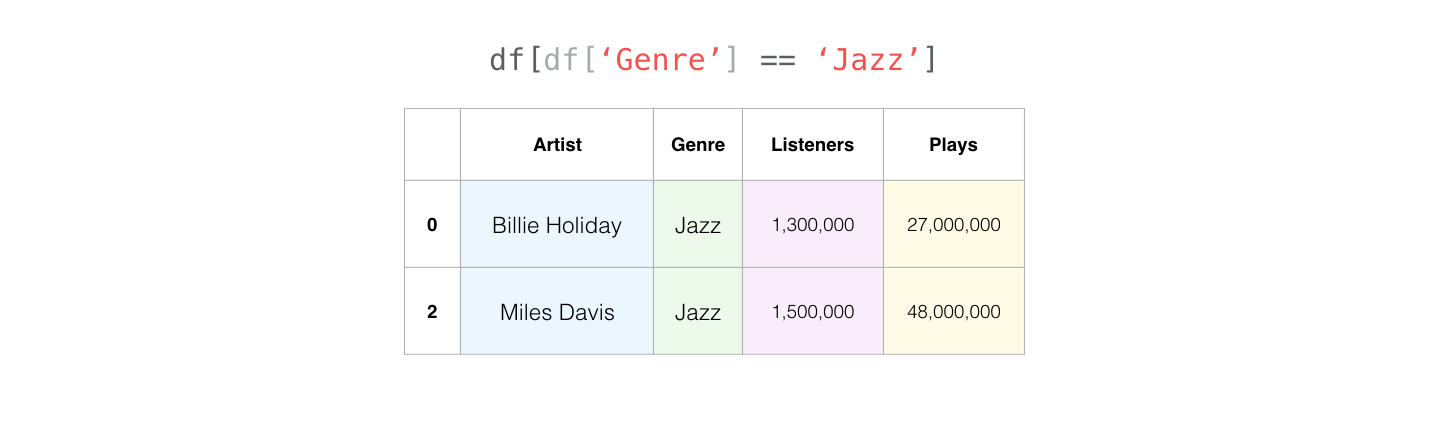
我们可以很容易地使用特定行的值来过滤行。例如,这里是我们的爵士乐手:
练习:过滤元素¶
选择 Genre 是 "Rock"的行
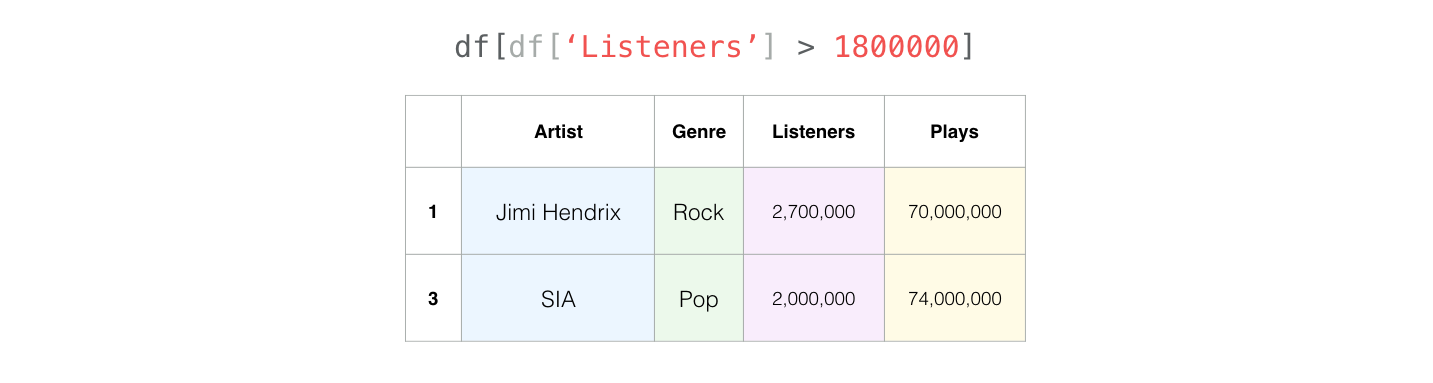
以下是拥有超过180万名听众的艺术家:
练习:条件过滤¶
选择 "Plays "小于50,000,000的行
4. 分组¶
当你开始用某些标准对行进行分组并汇总它们的数据时,事情就会变得非常有趣。例如,让我们按流派"Genre"对我们的数据集进行分组,看看每种流派有多少听众和播放次数:
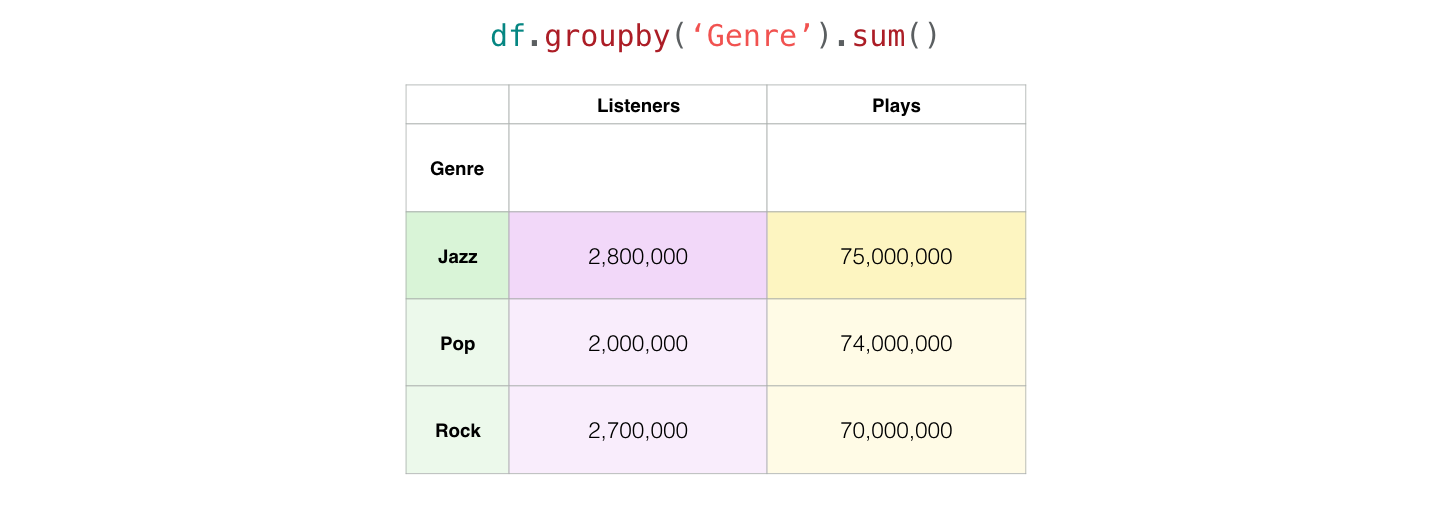
Pandas将两行 "Jazz"爵士乐归为一行,由于我们使用了sum()聚合,它将两位爵士乐艺术家的听众和播放次数加在一起,并将总和显示在合并的"Jazz"列中。
这不仅有趣,而且是一种极其强大的数据分析方法。现在你知道了groupby(),你就可以折叠数据集并从中发掘出洞察力。
除了sum(),pandas还提供了多个聚合函数,包括计算平均值的mean(),min(),max(),以及其他多个函数。更多关于groupyby()的信息请参见Group By用户指南。
练习:聚合¶
按"Genre"分组,使用sum()作为聚合函数
5. 从现有的列创建新的列¶
在数据分析过程中,我们经常发现自己需要从现有的列中创建新的列。Pandas让这一切变得轻而易举。
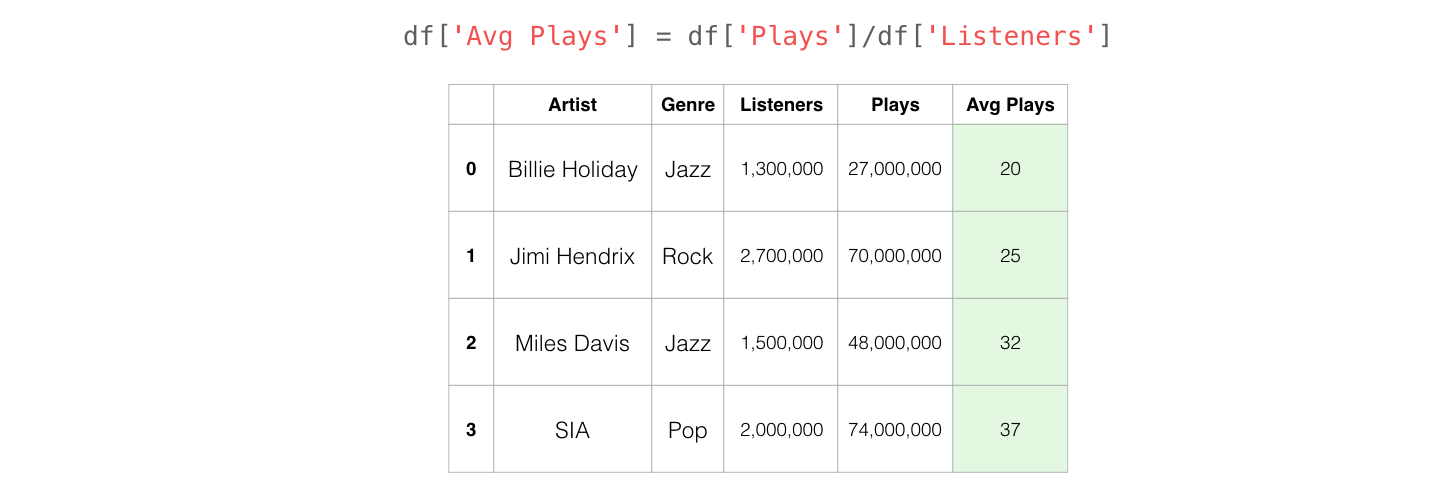
通过告诉Pandas用一列除以另一列,它意识到我们要做的是分别除以各个数值(即每行的 "Plays "值除以该行的 "Listeners "值)。
练习:创建新列¶
创建一个新列,列名为’Avg Plays’,值为每个艺术家的平均播放次数,即总播放次数’Plays’除以听众数’Listeners’。
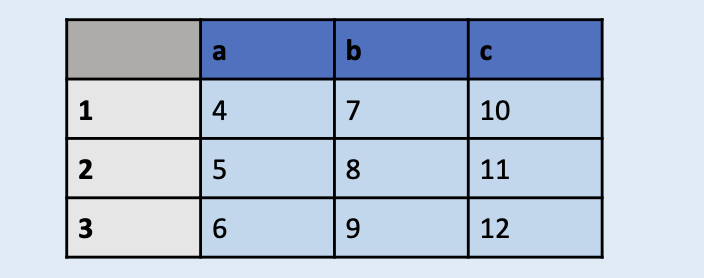
创建一个pandas.DataFrame对象,存储以上元素;
添加一个新列为’d’, 对应行1,2,3的值为13, 14, 15;
使用选取操作,选取’a’和’d’列;
使用切片操作,选取第0行和第1行;
参考¶
10 Minutes to pandas: https://
pandas .pydata .org /pandas -docs /stable /10min .html A Gentle Visual Intro to Data Analysis in Python Using Pandas: https://
jalammar .github .io /gentle -visual -intro -to -data -analysis -python -pandas/