4.3 描述性统计方法
1. 描述性统计方法¶
描述性统计方法是一种统计学方法,用于对数据进行总结、描述和分析。它通过计算、整理和展示数据的基本特征,帮助我们理解数据的分布、趋势和变异性。
常见的描述性统计方法包括:
中心趋势测量:包括均值、中位数和众数,用于描述数据的集中程度。
离散程度测量:包括方差、标准差和极差,用于描述数据的分散程度。
分布形态测量:包括偏度和峰度,用于描述数据的分布形状。
百分位数和四分位数:用于描述数据的位置和分布。
频数和频率分布:用于统计数据的出现次数和频率。
中英文词汇对照:
| 统计学里的描述性统计方法 | 中文 |
|---|---|
| Count | 个数 |
| Minimum | 最小值 |
| Maximum | 最大值 |
| Mean | 均值 |
| Median | 中位数 |
| Variance | 方差 |
| Standard deviation | 标准差 |
| Quintile | 分位数 |
1.1 平均值¶
均值是描述数据集中程度的重要指标。它可以用来表示数据的典型值或平均水平。通过计算均值,我们可以得到数据的中心位置,帮助我们理解数据的整体特征。
需要注意的是,均值对于极端值(异常值)比较敏感,因为它会受到这些值的影响。
练习¶
找到以下序列的平均值[2, 2, 4, 5, 5, 5, 8, 9, 9, 9, 12],可以使用numpy的mean()方法。
1.2 标准差¶
数据离散程度的度量最常用的指标就是方差和标准差。它的计算公式如下:
这里,...是我们的观测值、为均值。标准差越大,表示数据的离散程度越高;标准差越小,表示数据的离散程度越低。
练习¶
找到以下序列的标准差[2, 2, 4, 5, 5, 5, 8, 9, 9, 9, 12],可以使用numpy的std()方法。
1.3 中位数¶
顾名思义,一组数据的中位数是当以递减或递增顺序排列时出现在数据中间位置的数字,数据中位数不容易受极端值的影响。
练习¶
找到以下序列的中位数[2, 2, 4, 5, 5, 5, 8, 9, 9, 9, 12],可以使用numpy的median()方法。
1.4 分位数¶
四分位数是将分类的数据分成四个部分的三个数值,每个部分的观察值的个数都是相等的。四分位数是分位数的一种类型。
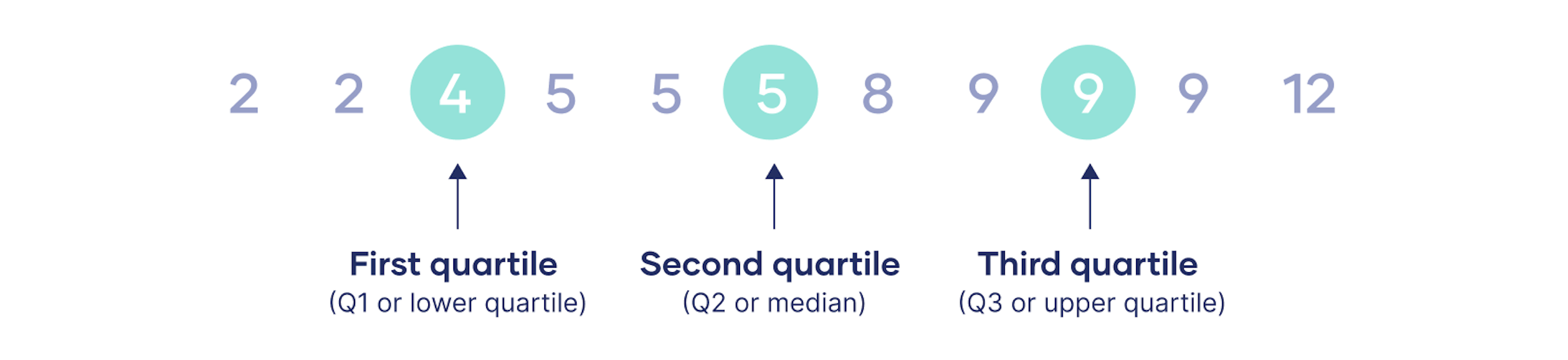
第一个四分位数(Q1,或最低四分位数)是第25个百分位数,意味着25%的数据落在第一个四分位数以下。
第二个四分位数(Q2,或中位数)是第50个百分位数,意味着50%的数据低于第二个四分位数。
第三个四分位数(Q3,或上四分位数)是第75个百分位数,意味着75%的数据落在第三个四分位数以下。
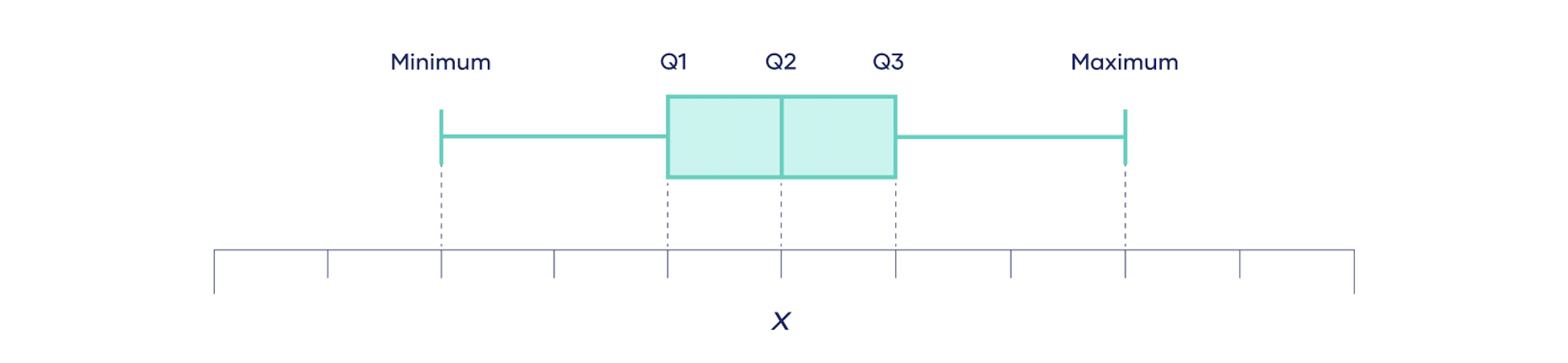
箱型图可以在视觉上很好得描述数据集的分位数,它们由显示四分位数的方框和显示最低和最高观测值的“须”组成:
练习¶
找到以下序列的75%分位数[2, 2, 4, 5, 5, 5, 8, 9, 9, 9, 12],可以使用numpy的np.quantile(a=数组、q=分位数)方法。
2.Pandas下的描述性统计方法¶
首先,加载一个数据集文件到内存里
import pandas
df=pandas.read_csv("datasets/world-happiness-report-china.csv", index_col=0)
df它返回的是一个pandas.DataFrame的对象,我们称之为“数据框”类型。
我们把它赋给变量名为df的变量。
如果只是想查看头和尾巴,可以使用dataframe.head()或者dataframe.tail()这两个方法。
df.head()2.1 describe方法¶
它会返回我们的数据集的一些基础的描述性统计信息。
df.describe()这些会按照每一列的数据进行统计,结果包括:
count : 个数
mean : 均值
std : 标准差
min : 最小值
25% : 分位数为25%的数值
50% : 分位数为50%的数值
75% : 分位数为75%的数值
max : 最大值
Pandas常用统计方法
| 函数名称 | 作用 |
|---|---|
| .count() | 非NA值的数量 |
| .min() | 最小值 |
| .max() | 最大值 |
| .mean() | 均值 |
| .median() | 中位数 |
| .var() | 方差 |
| .std() | 标准差 |
| .skew() | 偏度 |
| .kurt() | 峰度 |
如果我们想要计算某一列的最大值,可以这样:
df["幸福指数"].max()5.771同样,计算标准差,可以使用命令:
df["幸福指数"].std()0.33458043377739044练习:对东亚地区进行描述性统计分析¶
使用pandas.read_csv读取路径"datasets/world-happiness-report-2021.csv"文件,对"East Asia"东亚地区进行描述性统计分析,包括:
最大值
最小值
均值
标准差
分位数
2.2 包含缺失值的情况¶
当数据框包含缺失值时,比如
df["自由"]国家名称
China NaN
China NaN
China 0.853
China 0.771
China 0.805
China 0.824
China 0.808
China 0.805
China NaN
China NaN
China NaN
China 0.878
China 0.895
China 0.927
China 0.891
Name: 自由, dtype: float64统计这一列的个数,是不考虑缺失值的:
df["自由"].count()10计算平均值,也是同样自动忽略缺失值,然后计算的。
df["自由"].mean()0.8456999999999999