10.1 聚类的理论
聚类是一种无监督的学习,它将相似的对象归到同一个簇中。簇内的对象越相似,聚类的效果越好。 该算法可以应用于客户价值分析、文本分类、基因识别、卫星图片分析、商业客户归类等。
1. 聚类和分类的不同¶
聚类和分类的最大不同在于,分类的目标事先已知,而聚类则不一样。因为其产生的结果与分类相同,只是没有预先定义,聚类有时候也被称为无监督分类(unsupervised classification)。
聚类(Clustering) :是指把相似的数据划分到一起,具体划分的时候并不关心这一类的标签,目标就是把相似的数据聚合到一起,聚类是一种无监督学习(Unsupervised Learning)方法。
分类(Classification) :是把不同的数据划分开,其过程是通过训练数据集获得一个分类器,再通过分类器去预测未知数据,分类是一种监督学习(Supervised Learning)方法。
2. K-均值(K-Means)算法设计¶
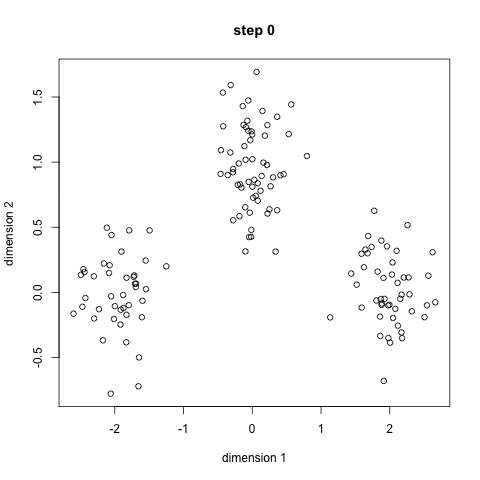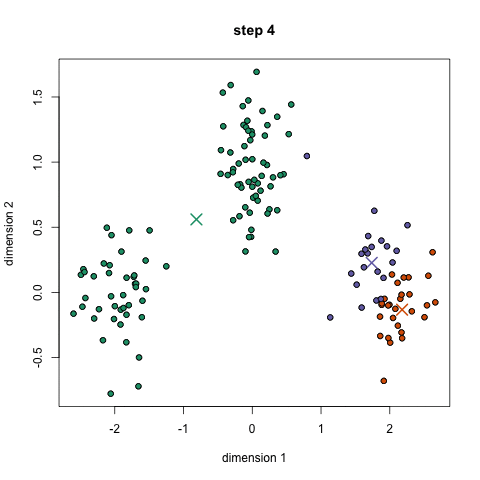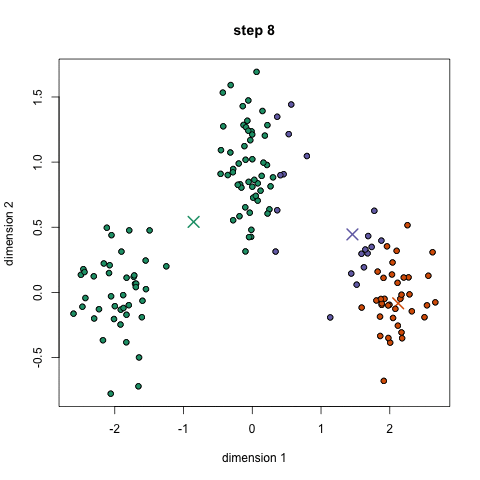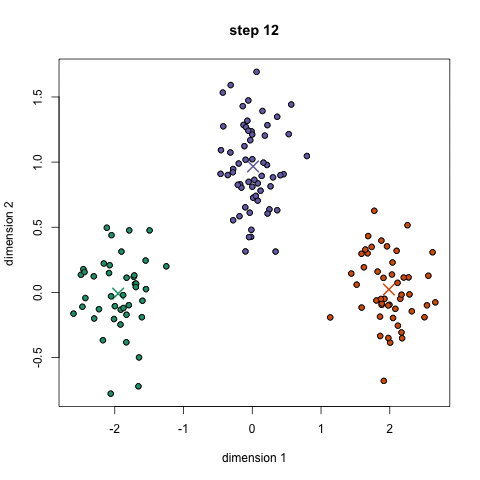
K均值(K-means)算法是一种常用的聚类算法,用于将数据点划分成 K 个不同的组或簇。 K是指聚类的类别数量。被归为一类的数据点组成一个簇(cu第四声)。 请问图中的K=?
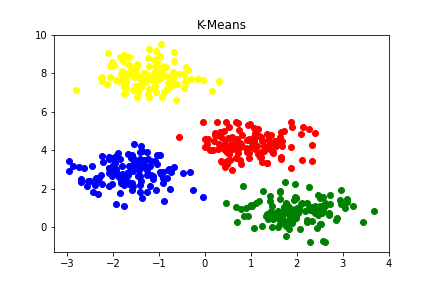
2.1 算法步骤¶
该算法的基本思想是将数据点划分为 K 个簇,使得每个数据点都属于离它最近的簇的中心(质心)。
K均值(K-means)算法分为3个步骤:
第1步,选择初始的簇中心,可以随机选择数据集中的样本;
第2步,使用相似度算法,计算样本和每个簇中心的距离,将每个样本分配到最近的簇中心所在的簇;
第3步,计算新的簇中心。
**重复迭代第2和3步,直到簇中心不再变化或达到最大迭代次数为止。
在第2步中,相似对象归入同一簇,将不相似对象归到不同簇。相似这一概念取决于所选的相似度计算方法。

在第3步中,如何计算簇的中心呢?我们考虑最简单的三个点组成的三角形的中心。
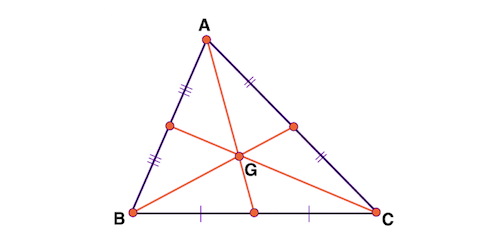
三角形的质心公式: 如果三角形顶点的坐标为 A(, ), B(, ), C(, ), 则三角形质心的公式如下: 三角形的质心= 。
2.2 动态演示¶
下面是K-Means算法的动态演示。
3. 聚类算法家族¶
当然,聚类算法不止K-Means一种。当数据集本身情况比较复杂,使得K-means聚类效果并不理想的时候,很多新的聚类算法被开发出来了。
3.1 DBSCAN¶
k-means算法对于凸性数据具有良好的效果,能够根据距离来讲数据分为球状类的簇,但对于非凸形状的数据点,就无能为力了,当k-means算法在环形数据的聚类时,我们看看会发生什么情况。
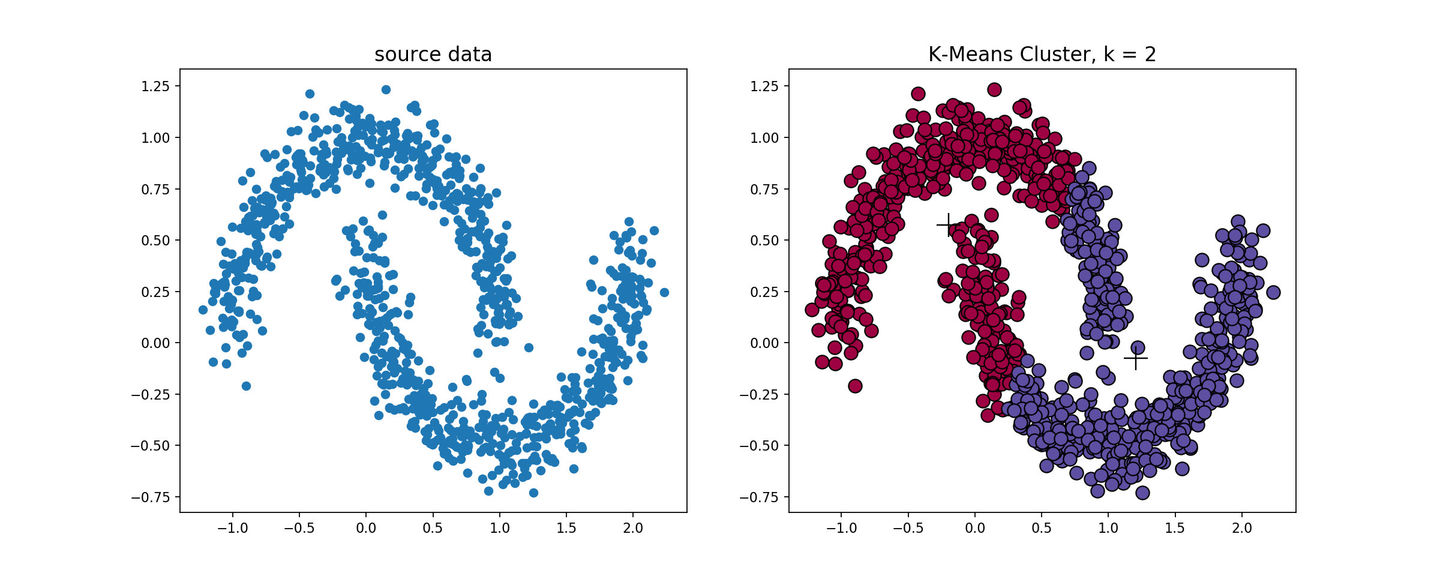
从上图可以看到,kmeans聚类产生了错误的结果,这个时候就需要用到基于密度的聚类方法了。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,适用于发现任意形状的簇,并能够有效地处理噪声数据。DBSCAN的基本思想是通过确定数据点周围的密度来识别簇。与K均值等算法不同,DBSCAN不需要事先指定要形成的簇的数量。
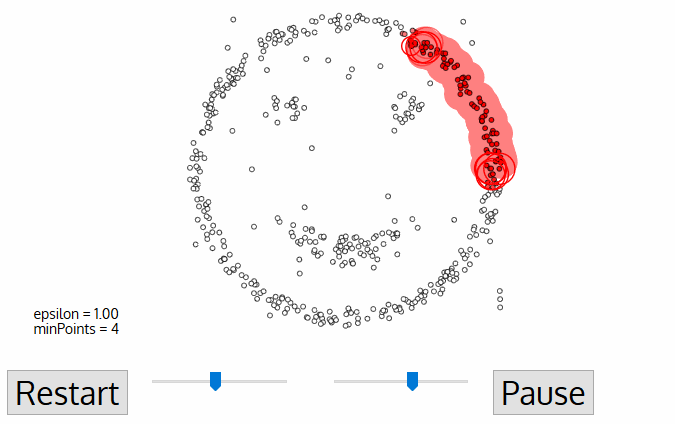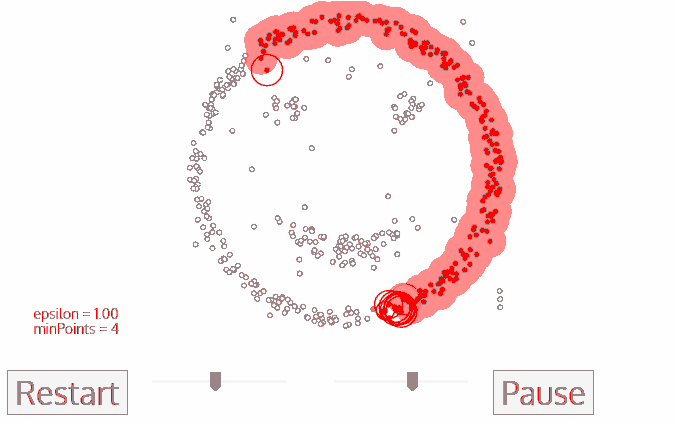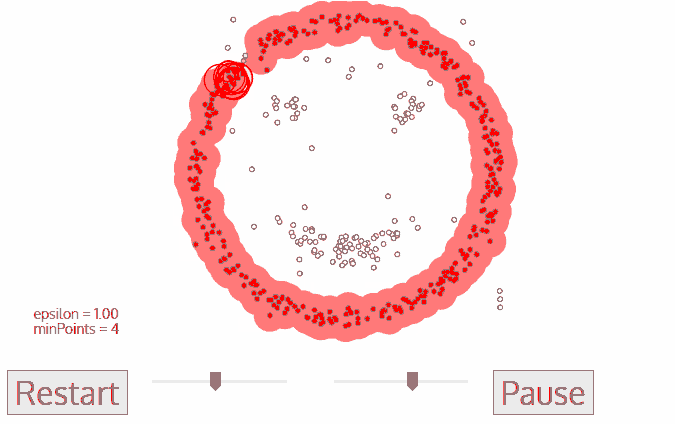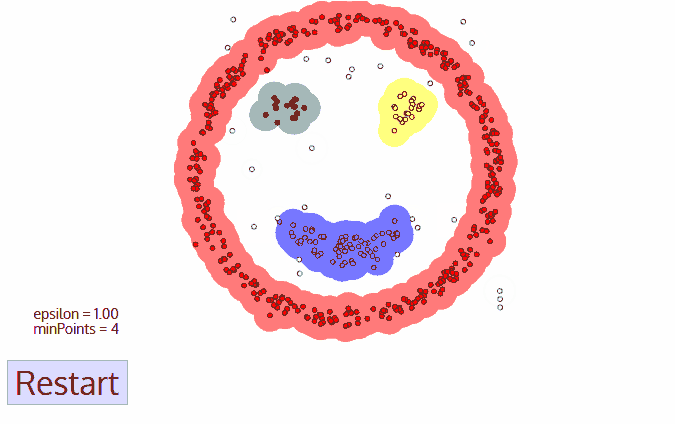
3.2 高斯混合¶
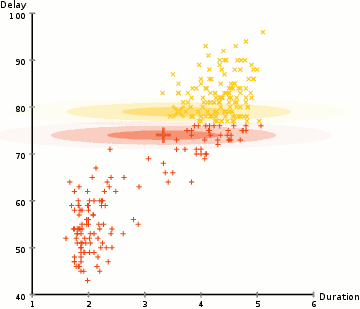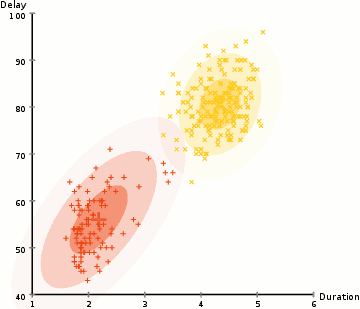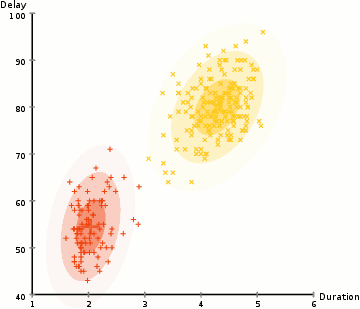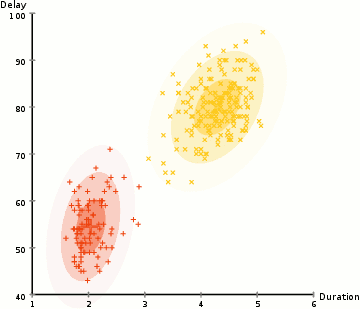
高斯混合模型(Gaussian Mixture Model,GMM)可以看做是k-means模型的一个优化。它假设数据是由多个高斯分布组成的混合体,每个高斯分布代表一个簇。GMM的基本思想是将数据点看作是从多个高斯分布中抽样而来的,通过调整每个高斯分布的参数来最大化观测数据的似然性。
GMM的概率密度函数是多个高斯分布的线性组合,表示为:
其中, 是数据点 的概率密度, 是高斯分布的数量, 是每个高斯分布的权重(满足 ), 和 分别是第 个高斯分布的均值和协方差矩阵。
3.3 层次聚类¶
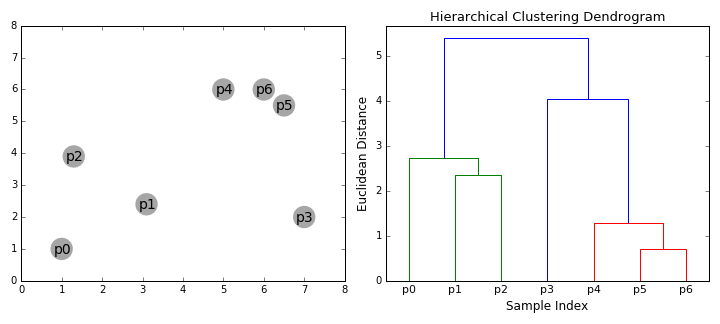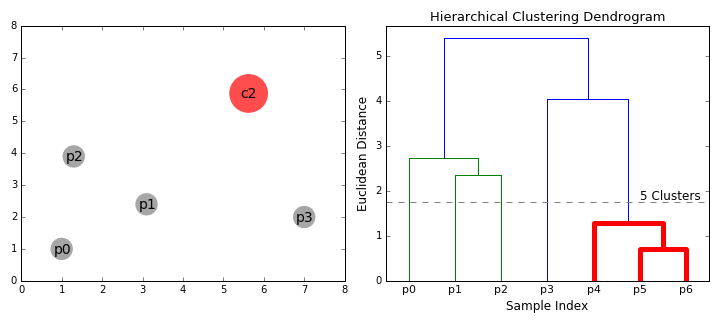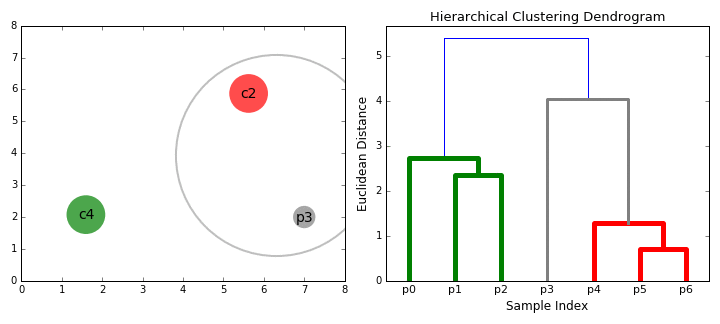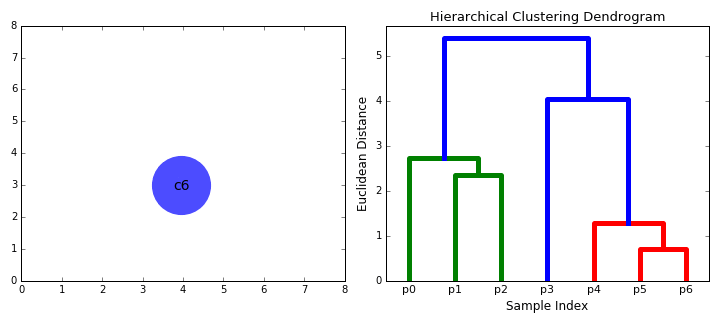
层次的聚类方法(Hierarchical Clustering),从字面上理解,其是层次化的聚类,最终得出来的是树形结构。专业一点来说,层次聚类通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。
其算法流程为:先将所有样本的每个点都看成一个簇,然后找出距离最小的两个簇进行合并,不断重复到预期簇或者其他终止条件。
练习¶
你是否已经掌握聚类算法理论?
请完成自我检测:https://