附录:训练集、测试集和交叉验证
1. 训练集VS测试集¶
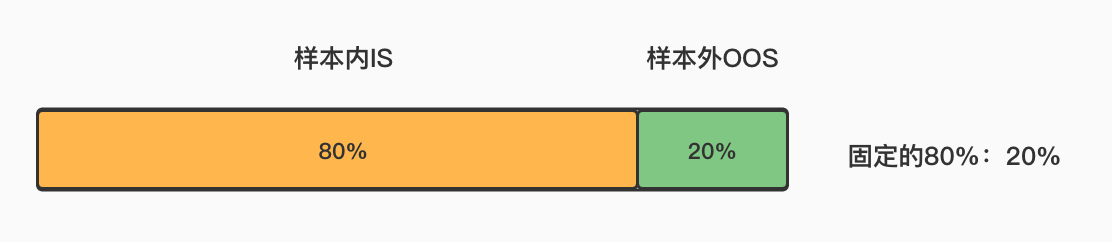
根据随机对照试验的理论,我们通常将数据集划分为训练集(training sets)和测试集(test sets),前者负责模型的训练任务,后者用来评价模型的表现。两者的划分比例按照经验,设置为0.8:0.2。
一般将80%的原始数据集的子样本集作为样本内(In-sample, IS),剩余20%作为样本外(Out-of-sample, OOS)。样本总数为500个,一种简单的切割方法是直接指定前80%个样本为IS,后面20%为OOS,但是这种采样方法存在弊端。
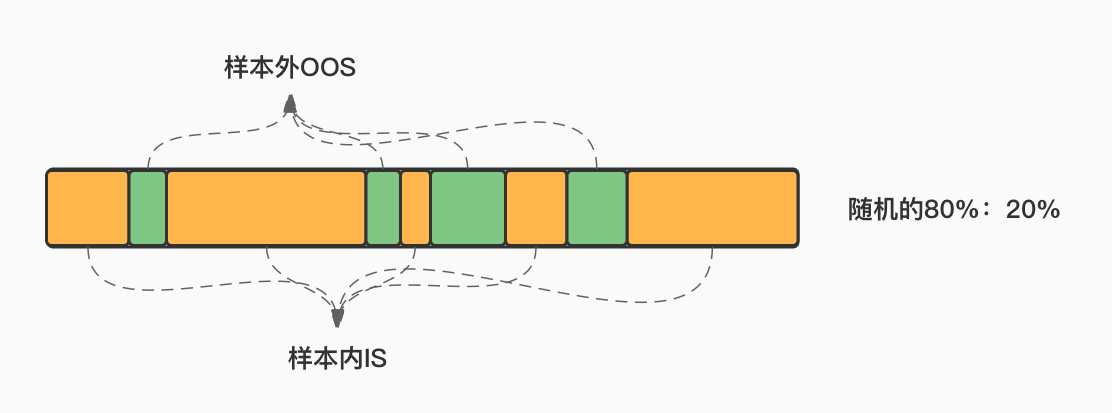
当我们并不了解原始数据集是不是被刻意排列了,最好的办法是使用随机抽样,即随机抽80%为IS,剩余的20%为OOS。我们使用生成随机数的方法,生成随机序列,来从总体样本中随机抽取样本:
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = \
train_test_split(x, y,train_size=0.8,random_state=42)进一步,我们可以将数据集分为“训练集”、“验证集”和“测试集”。
2. 验证集¶
在机器学习和深度学习中,“训练集”、“验证集”和“测试集”是常用的术语,用于划分数据集以评估模型的性能和泛化能力。
训练集(Training Set):
训练集是用于训练模型的数据集。模型通过观察训练集中的样本来学习特征和模式,并调整其参数以最小化训练误差。
验证集(Validation Set):
验证集是用于调整模型超参数(如学习率、正则化参数等)和评估模型性能的数据集。在训练过程中,模型使用训练集进行训练,然后使用验证集进行验证。通过比较模型在验证集上的表现,可以选择最佳的超参数配置,以防止模型对训练集过度拟合。
测试集(Test Set):
测试集是用于最终评估模型性能和泛化能力的数据集。一旦选择了最佳的模型和超参数配置,就可以使用测试集来评估模型在新样本上的表现。测试集的数据应该与模型之前未见过的数据相似,以确保评估结果的可靠性。
通常,数据集会被划分成训练集、验证集和测试集三部分。典型的划分比例是70%的数据用于训练,15%用于验证,15%用于测试,但具体的划分比例取决于数据集的大小和特性。
3. 交叉验证¶
即使在将数据分为训练数据和验证数据后进行评估,也依然可能发生过拟合。可以想到的原因是使用的训练数据和验证数据碰巧非常相似。反过来也有可能出现训练数据和验证数据非常不相似的情况。
为了避免这种数据分割的误差,可以使用不同的分割方案进行多次验证,这就是所谓的交叉验证(cross validation)。 本节以将数据分割 5 次,其中 80% 的数据用于训练,20% 的数据用于验证的情况为例进行说明。
如图所示,每次获取不同的 20% 的数据作为验证数据,重复 5 次。在这个例子中,20% 的数据是按分组顺序分别分割的,但在实际应用中,作为验证数据的 20% 的数据是随机抽取的。

以下代码非常轻松地将数据分成了 5 块,即运行 5 次,每次留下 20% 的数据用于训练后的验证。
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
cv = KFold(5, shuffle=True)
model_rfc_1 = RandomForestClassifier()
cross_val_score(model_rfc_1, X, y, cv=cv, scoring='accuracy')参考¶
秋庭伸也,《图解机器学习算法》