7.2 机器学习的类别
机器学习包含不同的种类。根据不同的输入数据,分类如下:
有监督学习
无监督学习
强化学习
下面我们依次详细地看一下。
1. 有监督学习¶
1.1 分类问题¶
有监督学习是将问题的答案告知计算机,使计算机进行学习并给出机器学习模型的方法。这种方法要求数据中包含表示特征的数据和作为答案的目标变量数据。
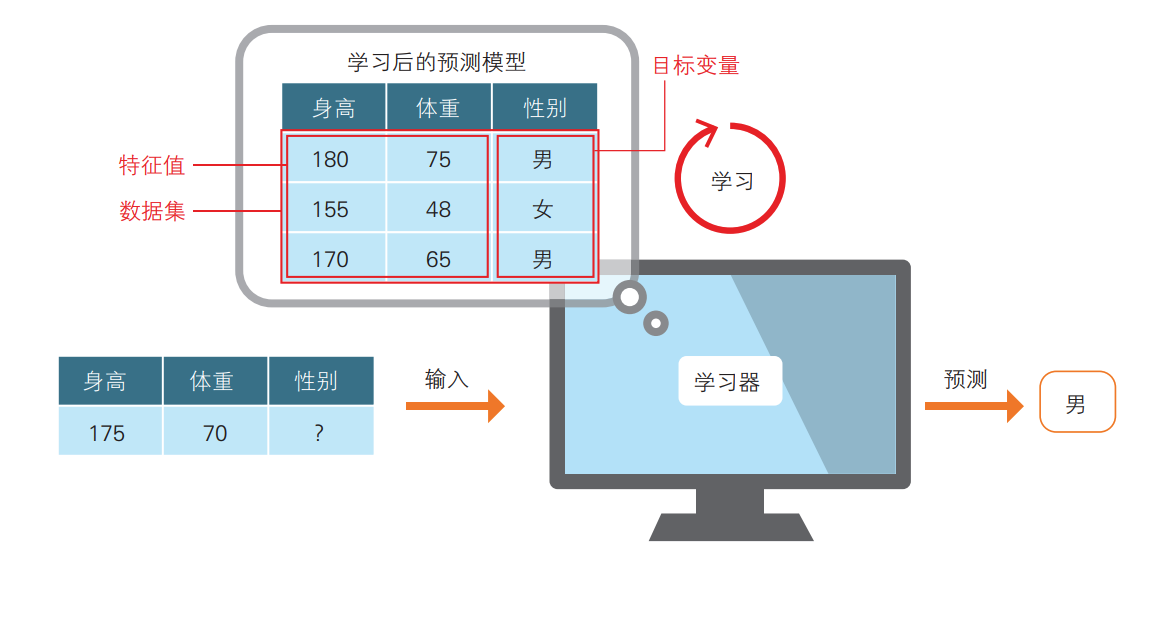
图 2 有监督分类的示意图
如图 2 所示,已有表示特征的身高和体重数据,作为答案的数据是性别(男 / 女)。我们向计算机提供这些数据的组合,使计算机进行学习并给出预测模型。然后,将新的身高和体重数据提供给模型,由模型预测出性别。
此外,表示特征的数据叫作特征值或者特征变量,作为答案的数据叫作目标变量或者标签。
1.2 回归问题¶
除了分类问题之外,有监督学习还包括回归问题。
如图3所示,已有表示特征的性别和身高数据,以及答案数据——鞋的尺码。在分类问题中,男和女的标签分别被数值化为 0 和 1,这两个 数值之间的大小关系是没有意义的。与之相对,鞋的尺码26.5 cm和24 cm之间的大小关系则是有意义的。对这样的数据进行预测的问题就是回归问题。
在回归问题中,目标变量是作为连续值处理的,所以预测值有可能是 23.7 cm 这种不存在的尺码。
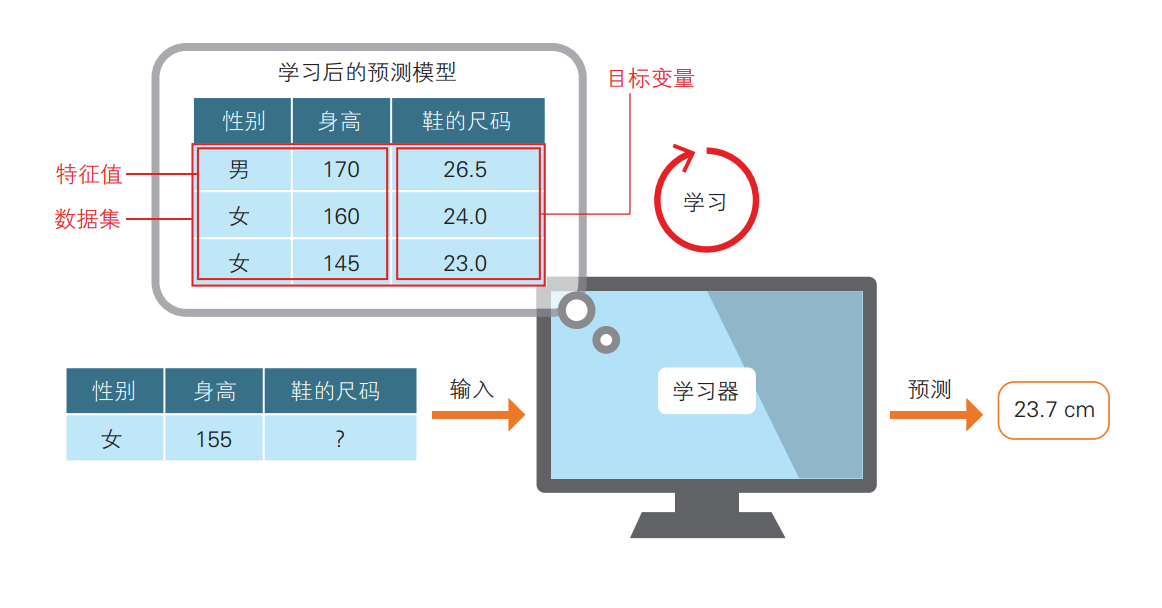
图 3 回归问题的示意图
2. 无监督学习¶
有监督学习是将特征值和目标变量(答案)作为一套数据进行学习的方法,而无监督学习的数 据中没有作为答案的目标变量。
有人可能会产生疑问:没有答案,该如何去学习呢? 无监督学习将表示特征的数据作为输入,通过将数据变形为其他形式或者找出数据中的部分集合,来理解输入数据的构造。此外,与有监督学习相比,无监督学习的结果难以解释,或者要求分析者基于经验加以主观的解释。有监督学习以“能否正确预测目标变量”为指标,相比之下,为了能够对结果进行解释,在进行无监督学习时, 用户需要对输入数据的前提知识有一定程度的了解。
这里举一个无监督学习的例子。我们思考一下对某个中学的学生成绩进行分析的场景。假设各科目之间存在着这样的关联性:擅长数学的学生也擅长理科,但不擅长语文和文科。
对于这样的输入数据,在使用无监督学习的代表性算法主成分分析(Principal Component Analysis,PCA)时,我们引入了新的轴,以说明被称为第一主成分的数据。在第一主成分上的坐标可以解释为“小值表明该生擅长理科,大值表明该生擅长文科”,如表所示,可以将数学、理科、语文、文科这 4 个特征值归纳在 1 个轴上加以展示。
表1 PCA的例子

这个例子使用 PCA 通俗易懂地解释了分析结果,但是需要根据输入数据选择合适的算法。 近年来,无监督学习的研究在图像和自然语言处理方面取得了进展,是当前备受瞩目的领域。这里介绍的 PCA 属于降维算法。降维是以更少的特征值来理解数据的算法。

图 聚类算法的可视化
无监督学习中也包括聚类算法。聚类是将数据分类为几个簇(相似数据的集合)的算法。人类很难直接理解多变量数据(由 3 个以上的变量构成的数据),通过聚类,数据能够以簇这种简单的形式进行展现。
3. 强化学习¶
强化学习是以在某个环境下行动的智能体获得的奖励最大化为目标而进行学习的方法。
这里简单地介绍一下强化学习。在主机游戏(环境)中,玩家(AI)为了获得分数(奖励)并取得最终的胜利,会无数次地重复尝试。我们也可以把强化学习看作有监督学习的目标变量被作为奖励提供的情况。拿主机游戏的例子来说,由于全部场景下所有操作的组合实在太多,很难通过人力进行评估,所以可以将游戏的场景和操作作为特征值,将游戏赛点作为目标变量,玩家无须依赖人力,通过无数次的游戏即可自行收集特征值和目标变量的数据组。强化学习在重复地玩游 戏、查看结果中不断学习更恰当的行动。