3.2 Numpy的一维数组
1. Numpy的数组介绍¶
在学习python基础编程时,我们已经掌握了列表(Lists)的创建和使用。Numpy中的有一种数据结构叫:数组(Arrays)。它和Lists有什么不同呢?
Numpy 数组比列表运行速度更快,更省计算机资源。
作为NumPy中主要的数据结构,数组是一些值组成的网格,它包含关于原始数据的信息,以及如何定位元素,意思是可以以各种方式对其进行索引。这些元素都是相同的类型,称为数组dtype。
数组被称为“ndarray”,它是“n维数组”的简写,d是单词dimension的缩写。n维数组就是具有任意维数的数组。你可能还听说过一维数组,二维数组,等等。NumPy ndarray用于表示矩阵和向量。向量是一维的数组(行向量和列向量没有区别),而矩阵是二维的数组。对于三维或更高维度的数组,张量这个术语也常用。
数组通常是固定大小的容器,包含相同类型的项。数组中的维数和项数由数组的形状定义。数组的形状是由非负整数组成的元组,指定每个维度的大小。
在NumPy中,维度称为轴。这意味着如果你有一个像这样的2D数组:
[[0., 0., 0.],
[1., 1., 1.]]数组有两个轴。第一个轴的长度是2,第二个轴的长度是3。
2.如何创建一个一维数组¶
2.1 创建一维数组¶
import numpy as np
np.array([1, 2, 3])array([1, 2, 3])用一种可视化方式来理解:

创建数组的时候,可以指定其中元素的类型,使用参数dtype。dtype可以等于np.int64, np.float64, np.str等等。
虽然默认的数据类型是浮点数(np.float64),但您可以使用dtype关键字显式指定想要的数据类型。
a = np.array([1, 2, 3, 4, 5, 6], dtype=np.float64)
aarray([1., 2., 3., 4., 5., 6.])练习:创建一维数组¶
请创建一个包含以下元素的一维数组:3.1, 5.2, 2.9, 6.6, 3.4, 5.5, 4.7。
2.2 数组的形状和尺寸¶
ndarray.ndim 会告诉你数组的轴数,或者说是维度。
ndarray.size 会告诉你数组元素的总数。这是数组的形状元素的乘积。
ndarray.shape 将显示一个整数元组,该元组指示数组每个维度上存储的元素数量。
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6])print('维度:', arr.ndim)
print('尺寸:', arr.size)
print('形状:', arr.shape)维度: 1
尺寸: 6
形状: (6,)
3. 几种生成常见数组的方法¶
除了指定每个元素来创建数组之外,你还可以轻松创建一个由0填充的数组,或者由1填充的数组,或者是创建一组随机数。
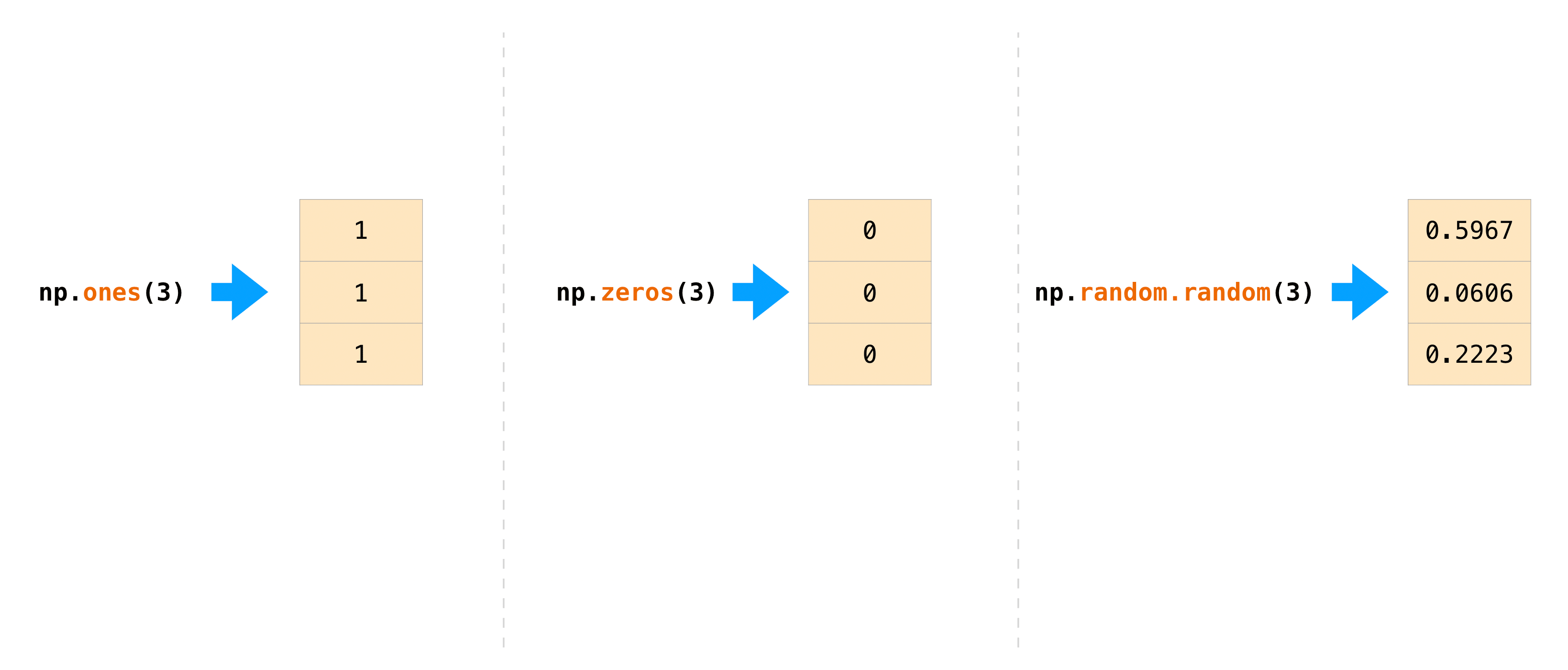
包含指定范围的数组:
np.arange(4)array([0, 1, 2, 3])甚至包含等距间隔的数组。为此,您需要指定第一个数字、最后一个数字和步长。下面这个例子,就是从2开始,到9结束,间隔为2。
np.arange(2, 9, 2) #step=2array([2, 4, 6, 8])你也可以使用np.linspace()来创建一个数组,该数组的值按指定的间隔线性排列:
np.linspace(0, 10, num=5)array([ 0. , 2.5, 5. , 7.5, 10. ])练习:生成等差数列¶
生成以一个等差数列:
4.索引和切片¶
您可能希望获取数组的一部分或特定数组元素,以便在进一步的分析或其他操作中使用。要做到这一点,您需要对数组进行子集、切片或索引。
就像使用列表(lists)一样,你可以用同样的方式索引和切片,选择数组中的部分元素。下面用一种可视化的方式:
 代码如下:
代码如下:
data = np.array([1,2,3])
data[0]1data[1] 2data[1:]array([2, 3])data[-2:]array([2, 3])练习:选取数组元素¶
给定下列数组[52, 11, 26, 35, 41, 71],请选取出部分元素:[26, 35], 再倒序选取[35,41]。
练习:数据集划分——固定划分¶
在机器学习中,样本内和样本外是指数据集中的一部分样本,其中来说,样本内是指用于训练模型、调整模型参数、验证模型性能的数据;样本外是指未在训练过程中使用的数据,通常用于测试模型的性能和泛化能力。这些相关知识点,会在后面章节学习到。
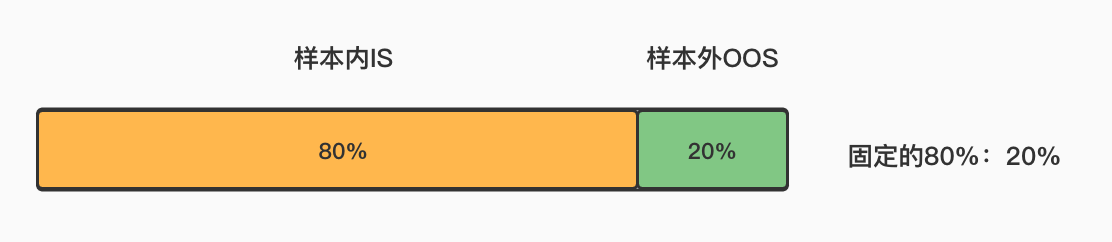
一般将80%的原始数据集的子样本集作为样本内(In-sample, IS),剩余20%作为样本外(Out-of-sample, OOS)。 样本总数为500个,一种简单的切割方法是直接指定前400个样本为IS,后面为OOS。
X = np.array([0.36707772, 0.30442107, 0.09602864, 0.72140911, 0.30727176,
0.30332833, 0.82704939, 0.0547752 , 0.91921485, 0.54352647,
0.45263199, 0.1654269 , 0.42571673, 0.38253443, 0.11461271,
0.56558215, 0.78277293, 0.82637154, 0.48652071, 0.49557472])如果给定一个X序列,那么其样本内和样本外分别是:
X_IS =
X_OOS = 5.数组的操作方法¶
5.1 排序数组元素¶
使用np.sort()对元素进行排序很简单。您可以在调用函数时指定轴、类型和顺序。
import numpy as np
arr = np.array([2, 1, 5, 3, 7, 4, 6, 8]) #使用np.array创建一个1维无序数组你可以按照升序进行排序:
np.sort(arr)array([1, 2, 3, 4, 5, 6, 7, 8])5.2 数学运算¶
一旦创建了数组,就可以开始使用它们了。比如说,你创建了两个数组,一个叫data,一个叫ones,它们之间的数学运算为:
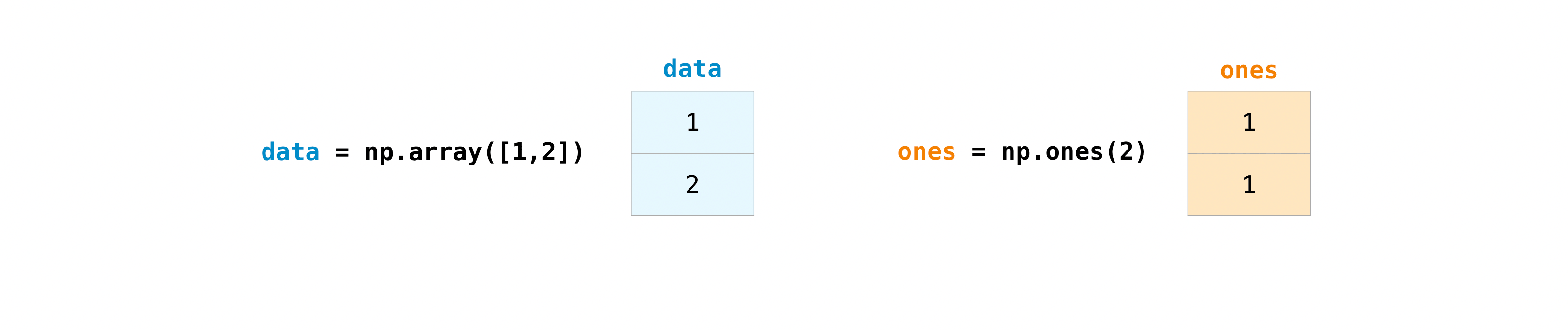
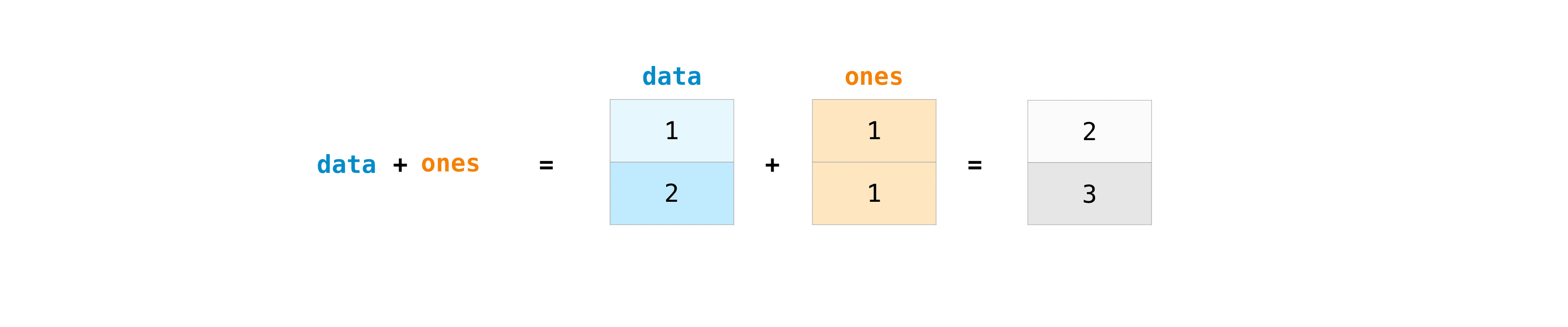
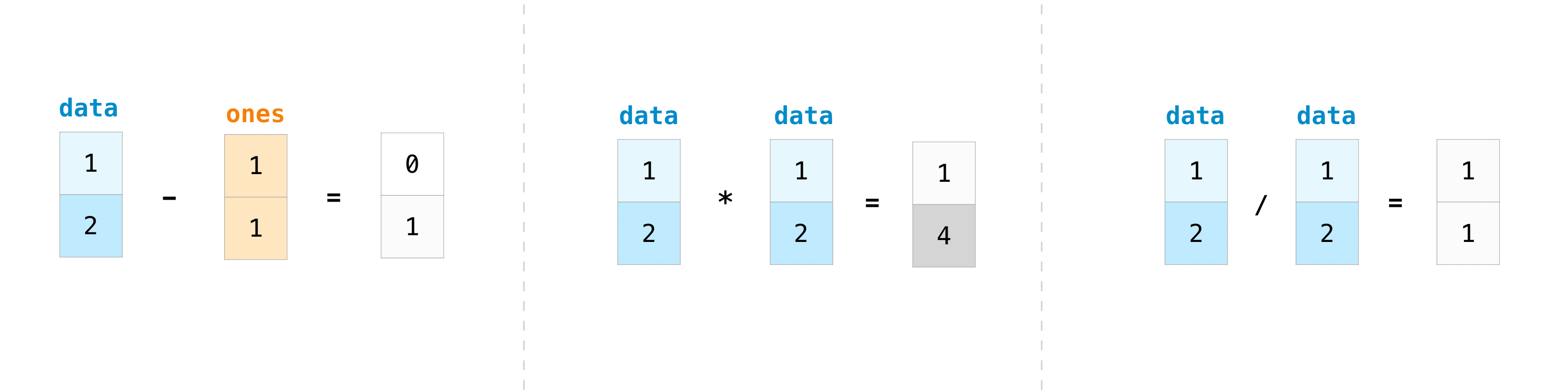
代码如下:
data = np.array([1, 2])
ones = np.ones(2, dtype=int)
data + onesarray([2, 3])data - onesarray([0, 1])data * dataarray([1, 4])data / dataarray([1., 1.])5.3 求和、最大值、最小值¶
NumPy还执行聚合函数。除了min、max和sum之外,您还可以轻松地运行mean以得到平均值,prod以得到元素相乘的结果,std以得到标准差,等等。
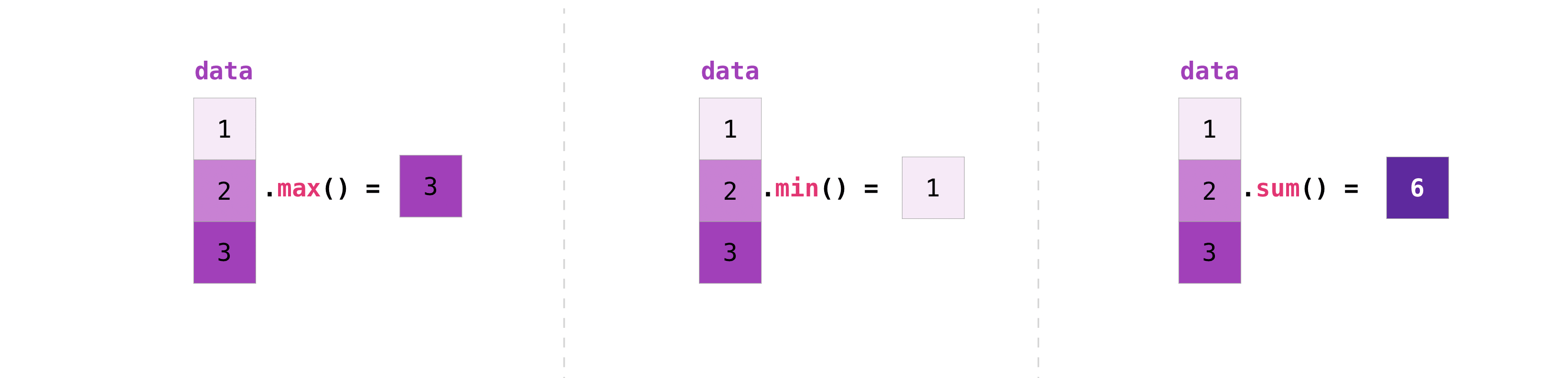
data = np.array([1, 2, 3])
print('序列[1,2,3]\n最大值:\t%i\n最小值:\t%i\n总和:\t%i'
%(data.max(), data.min(), data.sum()))序列[1,2,3]
最大值: 3
最小值: 1
总和: 6
练习: 评估销售信息¶
假设有一个销售数据集:[100, 150, 200, 120, 180, 90, 160, 220, 130, 190],
计算销售数量的总和
计算销售数量的平均值
计算销售数量的标准差
练习:最小最大标准化¶
最小最大标准化(Min-Max Normalization)是一种常用的数据标准化方法,用于将数据缩放到指定的范围内。 该方法通过对数据进行线性变换,使其值域被缩放到指定的范围内,通常是 [0,1] 或 [-1,1]。
该方法的公式如下:
通过最小最大标准化,可以使得不同量纲的数据在同一标度下进行比较,且可以使得数据具有可比性。 在机器学习、数据挖掘等领域中,常常需要对数据进行标准化,以提高算法的性能和效果。
应用上述方法,将序列[16, 46, 33, 90, 64, 34, 91, 33, 24, 32, 30, 91, 85, 58, 77, 35, 1,34, 51, 36]进行最小最大标准化操作,放缩到[0,1]。
5.4 包含随机数的数组¶
在很多实际场景中,我们需要使用随机数,NumPy包提供了random模块,使用np.random.函数名方法调用,可以使用help(np.random.函数名)或np.random.函数名?来查看函数参数和具体使用方法。
| 函数 | 作用 |
|---|---|
| random | 生成一个符合均匀分布[0,1)的随机数 |
| permutation | 随机排序序列或生成一个随机序列 |
| choice | 给定1维数组进行随机采样 |
| rand | 生成均匀分布的值 |
| randn | 生成正态分布的值 |
| randint | 给定范围生成均匀分布的整数 |
| seed | 为随机数生成器添加种子 |
例如,给定一个序列[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],我们可以进行随机排序:
arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr = np.random.permutation(arr)
arrarray([9, 2, 7, 8, 0, 6, 4, 1, 3, 5])练习:数据集划分——简单随机划分¶
简单随机划分(Simple Random Sampling):将原始数据集随机划分为训练集和测试集两部分,通常将数据集的 70% 到 80% 作为训练集,剩余部分作为测试集。
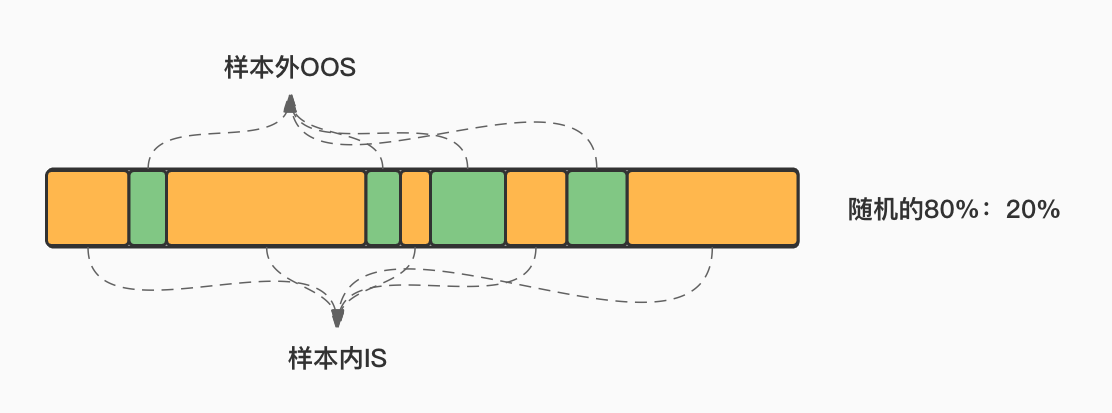
当我们并不了解原始数据集是不是被刻意排列了,最好的办法是使用随机抽样,即随机抽80%为IS,剩余的20%为OOS。
X_random_IS =
X_random_OOS = 6. 一个例子¶
实现在矩阵和向量上的数学公式是NumPy的一个关键用处,这也是为什么 NumPy 是python 科学计算领域的宠儿。
例如, 均方误差公式是解决回归问题的有监督机器学习模型的一个关键。
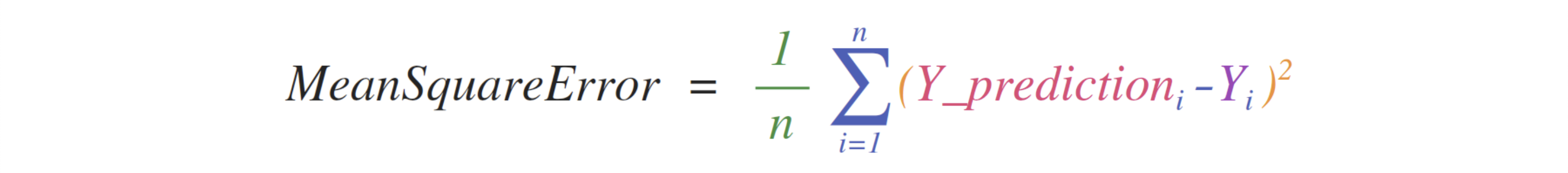
用 NumPy 来实现是一件轻而易举的事:

优雅之处在于 numpy 不关心 predictions 和 labels 的容量是 1 还是几百个值(只要它们有同样的容量)。我们可以通过如下四个步骤来对这行代码进行一个序列解读:

predictions 和 labels 向量都有3个值,也就是说 n = 3, 计算完减法后,我们得到如下的公式:

然后对这个向量求平方操作:

现在,我们对三个数进行求和:

error 中的值就是模型预测的误差。
练习:设计一个计算均方误差的函数¶
给定Y(或称为label)序列值为[10.1, 9.8, 10.5, 10.0, 10.3], 其预测的结果,也就是predictions为[10, 10, 10, 10, 10]时,MSE的值是多少?
7. 保存数组¶
需要将数组从内存中保存到文件时,可以使用NumPy的save()函数来保存数据为.npy格式。下面是一个示例代码:
import numpy as np
# 创建一个示例数据
data = np.array([1, 2, 3, 4, 5])
# 保存数据为.npy文件,存放在路径"datasets/"下
np.save('datasets/example_data.npy', data)
参考¶
NumPy: the absolute basics for beginners, https://
numpy .org /doc /stable /user /absolute _beginners .html A Visual Intro to NumPy and Data Representation, https://
jalammar .github .io /visual -numpy/