9.2 模型的性能评估
1. 精度与错误率¶
如何评估一个模型的好坏,一个自然而然的想法就是:模型给出的预测值与真实值进行对比。
错误率:分类错误的样本数占样本总数的比例
准确率(也称精度):分类正确样本数占样本总数的比例
精度计算如下:
2. 查全率与查准率¶
在二分类任务(类别为两类)中,假如我们定义’positive’ 和 ‘negative’ 为分类的预测结果, 而 ‘true’ and ‘false’ 指的是该预测是否符合
真正例(TP):实际为
正且预测为正的样本数。假正例(FP):实际为
负但预测为正的样本数。假负例(FN):实际为
正但预测为负的样本数。真负例(TN):实际为
负且预测为负的样本数。
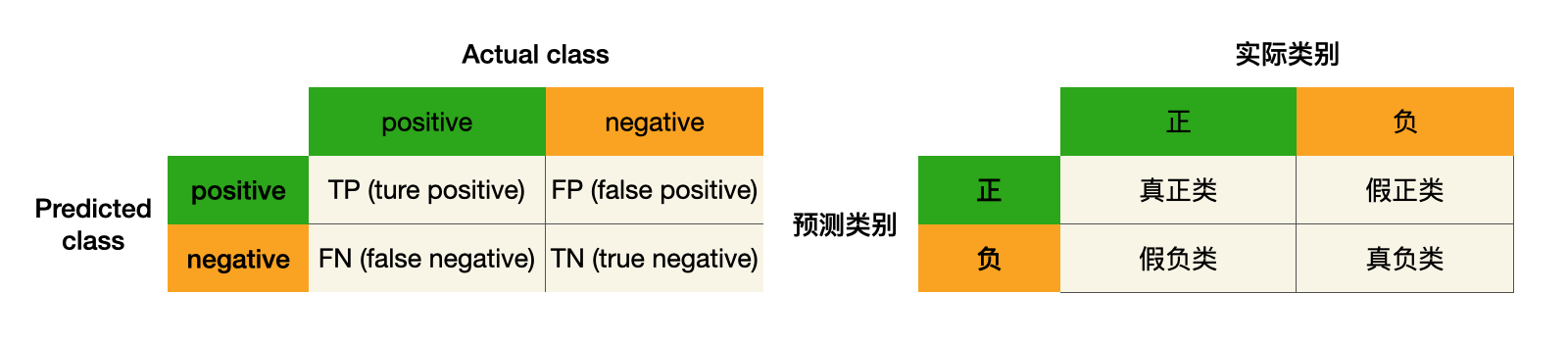
2.1 混淆矩阵¶
混淆矩阵(Confusion Matrix)
查准率(precision)
查全率(也叫召回率,recall)
从上图可以知道:
查准率:是基于「预测数据」,考察「真正例」的占比。
查全率:是基于「真实数据」,考察「真正例」的占比。
2.2 查准率:医疗诊断系统¶
医院使用一个分类模型来筛查癌症患者,将每个病人分类为“疑似癌症”或“非癌症”。
为什么需要高查准率:
避免不必要的惊慌:如果一个健康的人被错误地诊断为癌症(假正类,FP),会导致极大的心理压力和不必要的进一步检查。
资源浪费:误报会导致医院资源的浪费,因为健康患者可能会接受昂贵且不必要的后续测试和治疗。
假设筛查系统每天检查1000名患者,其中50人确实有癌症(正类),950人是健康的(负类)。模型预测出70个“疑似癌症”病例,其中40个是正确的(TP),30个是误报(FP)。
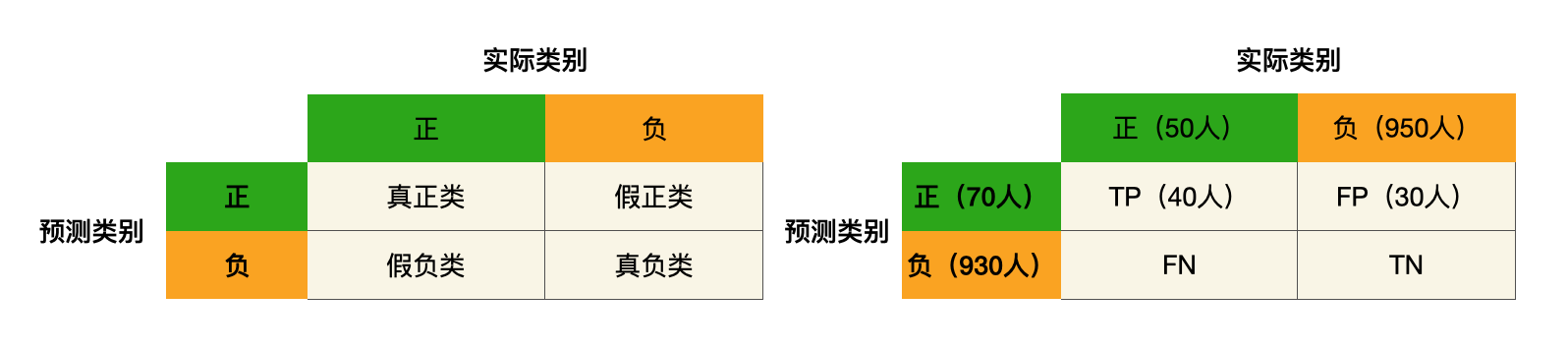
**查准率(Precision)**计算:
结果解释:
本次结果:57%被诊断为“疑似癌症”的患者确实是癌症患者
高查准率:如果精确率达到0.95以上,意味着几乎所有被诊断为“疑似癌症”的患者确实是癌症患者,减少了误报率。
低查准率:如果精确率较低,如0.5,则每两名被诊断为癌症的患者中就有一名实际上是健康的,这会造成不必要的恐慌和医疗资源的浪费。
在医疗诊断系统中,特别是癌症筛查,需要高查准率以确保诊断结果的可靠性和准确性,从而避免对健康患者的误诊和不必要的后续检查。
2.3 查全率:失踪儿童搜救系统¶
警方使用一个分类模型来筛查和识别可能的失踪儿童,将每个孩子的照片分类为“可能是失踪儿童”或“非失踪儿童”。
为什么需要高查全率:
确保尽可能多地找到失踪儿童:确保系统能够识别出所有失踪儿童是至关重要的。漏掉一个失踪儿童(假负类,FN)意味着一个孩子没有被找到,可能面临危险。
搜救行动:高查全率保证所有可能的线索都被考虑,从而增加找到失踪儿童的机会。
假设系统每天处理1000张儿童照片,其中20张是失踪儿童的(正类),980张是普通儿童的(负类)。模型预测出30张“可能是失踪儿童”的照片,其中15张是正确的(TP),15张是误报(FP),但有5个失踪儿童没有被识别出来(FN)。
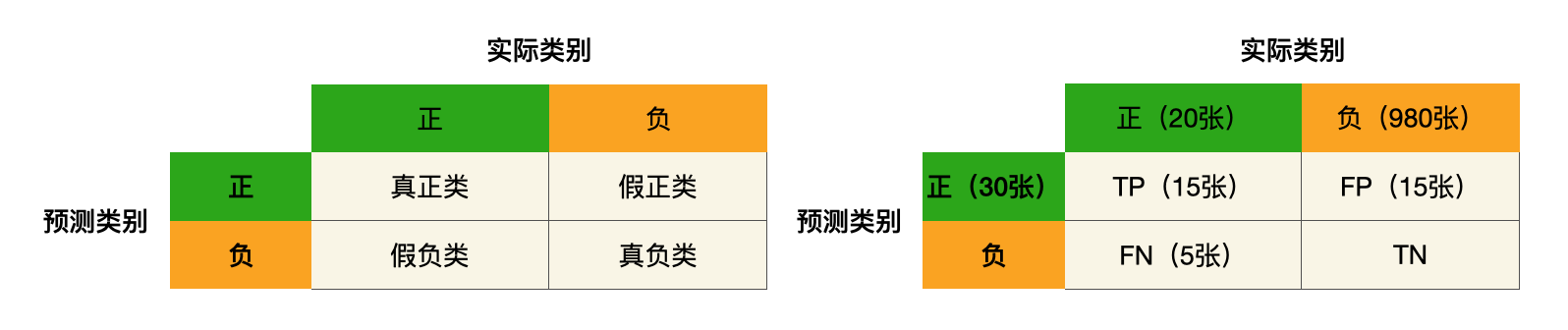
**查全率(Recall)**计算:
结果解释:
本次结果:75%的失踪儿童被识别出来了。
高查全率:如果查全率达到0.95以上,意味着几乎所有失踪儿童都会被识别出来,减少了漏报。
低查全率:如果查全率较低,例如0.5,则每两个失踪儿童中就有一个未被识别,这会严重影响搜救工作的效果。
在失踪儿童搜救系统中,优先考虑高查全率是至关重要的。这保证了大多数失踪儿童都能被识别并找到,从而避免孩子继续处于危险之中。