9.1 分类模型理论
1. 决策树的理论¶
决策树是监督学习中最常用、最实用的方法之一。它既可用于解决回归任务,也可用于解决分类任务,而其分类任务被更多地用于实际应用,如广告推荐、商户分类等。
我们以一个生活中常见的相亲例子,来开启决策树的介绍和讨论:
一个眼光略高对自己婚姻伴侣略有要求的女青年刘小姐,熟练得在相亲网站上筛选着相亲对象。
这个相亲网站有超过10万个真实注册用户,她固然可以直接设置一定的筛选规则,例如:“年龄在25~35之间”,“收入在中档以上”,“相貌较好”等条件,让网站在数据库里检索。
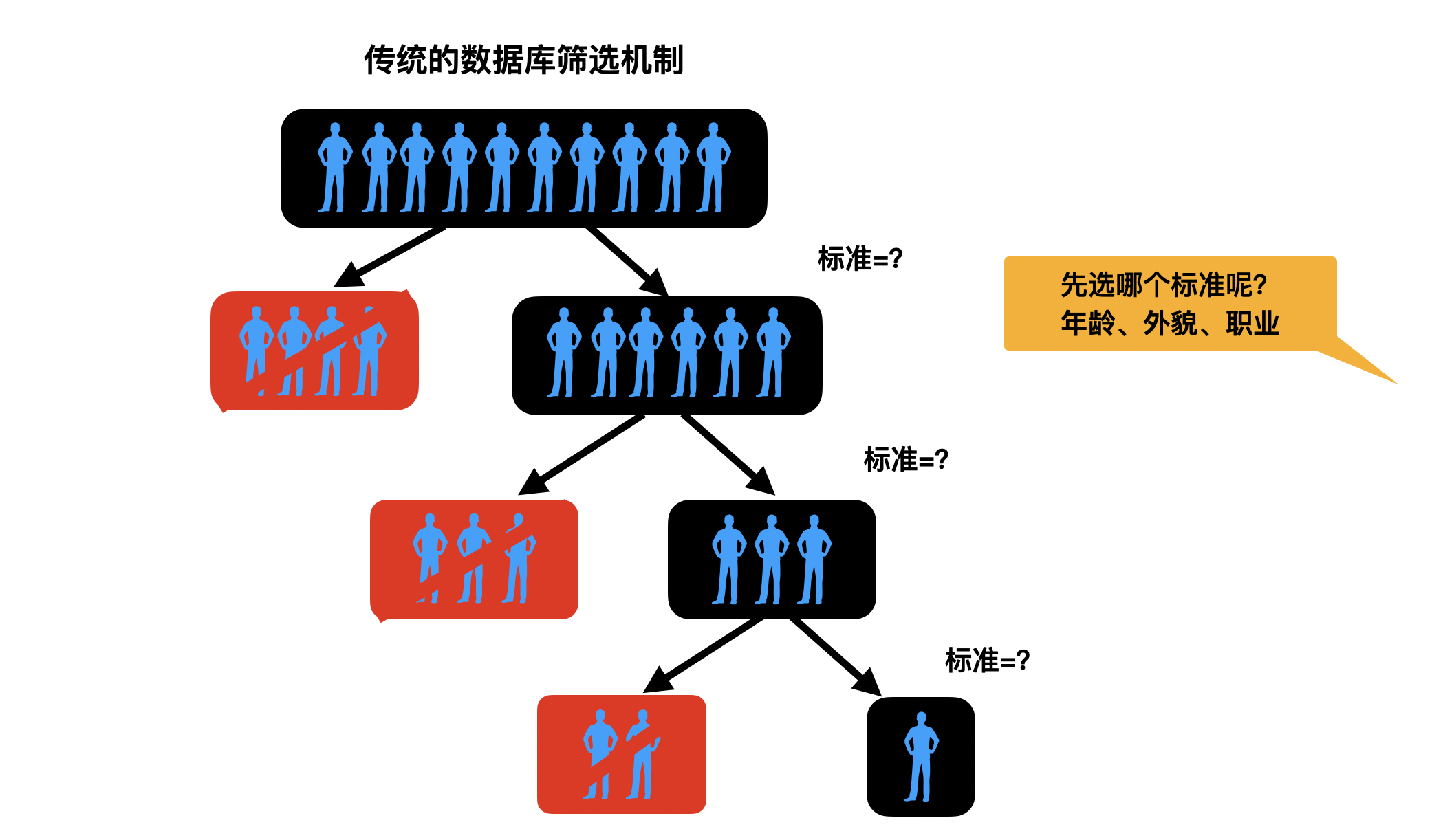
但是你已经意识到了,这样的规则会过滤掉不符合其中一些条件,但是在其他条件上却很好的男性。有没有什么方法来解决这个问题呢?
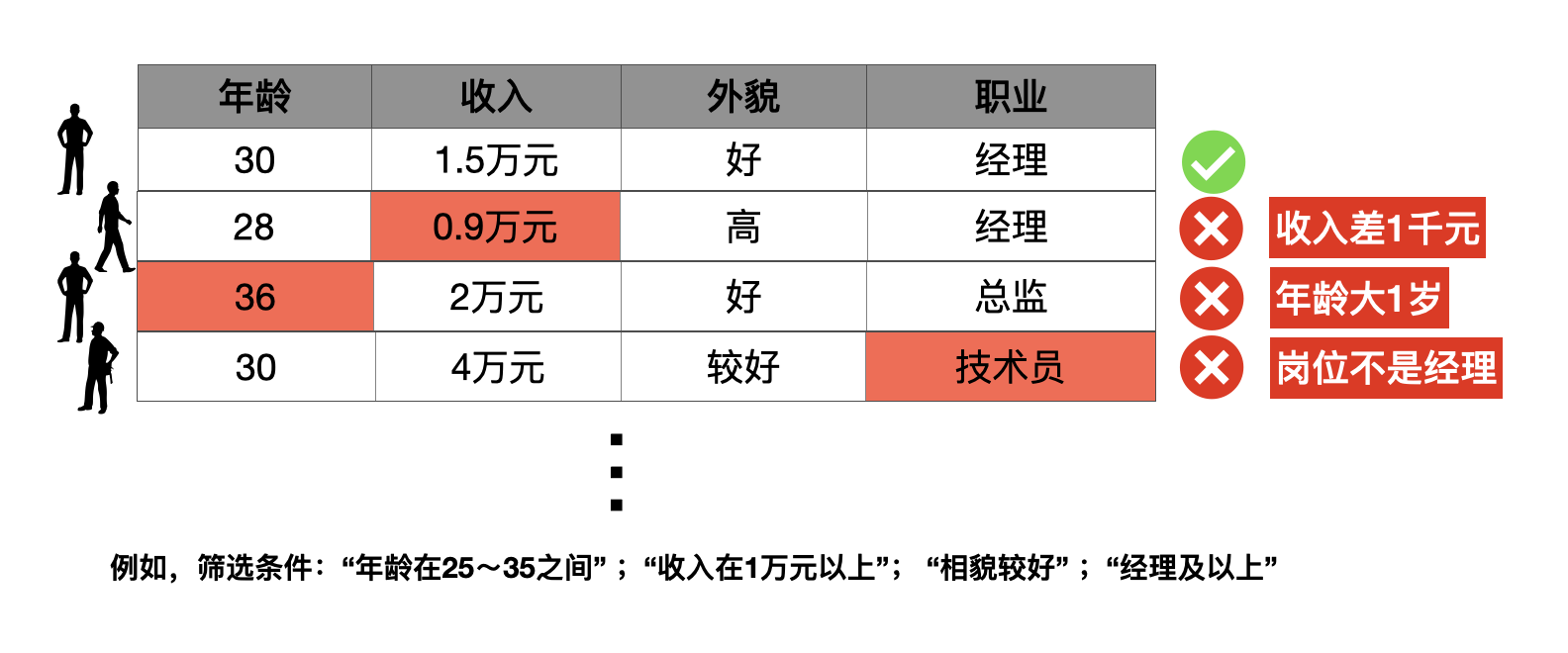
同时,当有新的男士资料被添加到服务器,刘小姐也不是每时每刻都在线,错过了,如何是好?
我们希望用机器学习的方法,让机器习得刘小姐对于另一半的偏好。这样,机器就可以24小时全天候帮她把关,并及时通过短信和邮件通知刘小姐。
2. 模型的训练和预测过程¶
首先,准备数据样本:
1)根据过去的浏览记录,将刘小姐点“👍”的男士样本打上标签,“Yes”,点“👎”或者拉黑的男士样本打上“No”;
2)根据随机对照实验理论,将样本分为样本内(IS)和样本外(OOS),比例可设为8:2,前者用来训练模型,后者用来验证模型的分类能力 ;
2.1 样本内(IS)训练过程¶
训练过程如下:
从上至下的方向,创建决策树的根节点,将样本内的数据集放入根节点中;
依次选择各个属性,对属性的数值进行划分(大于等于属性的某个值和小于这个属性值),并计算划分后的纯度;
选择划分后纯度最高或者标签一致的属性,作为当前分叉的标准,标签一致的为叶节点,另一个为中间节点;
回到步骤3,并重复执行1-3,直到所有中间节点都划分为叶节点。
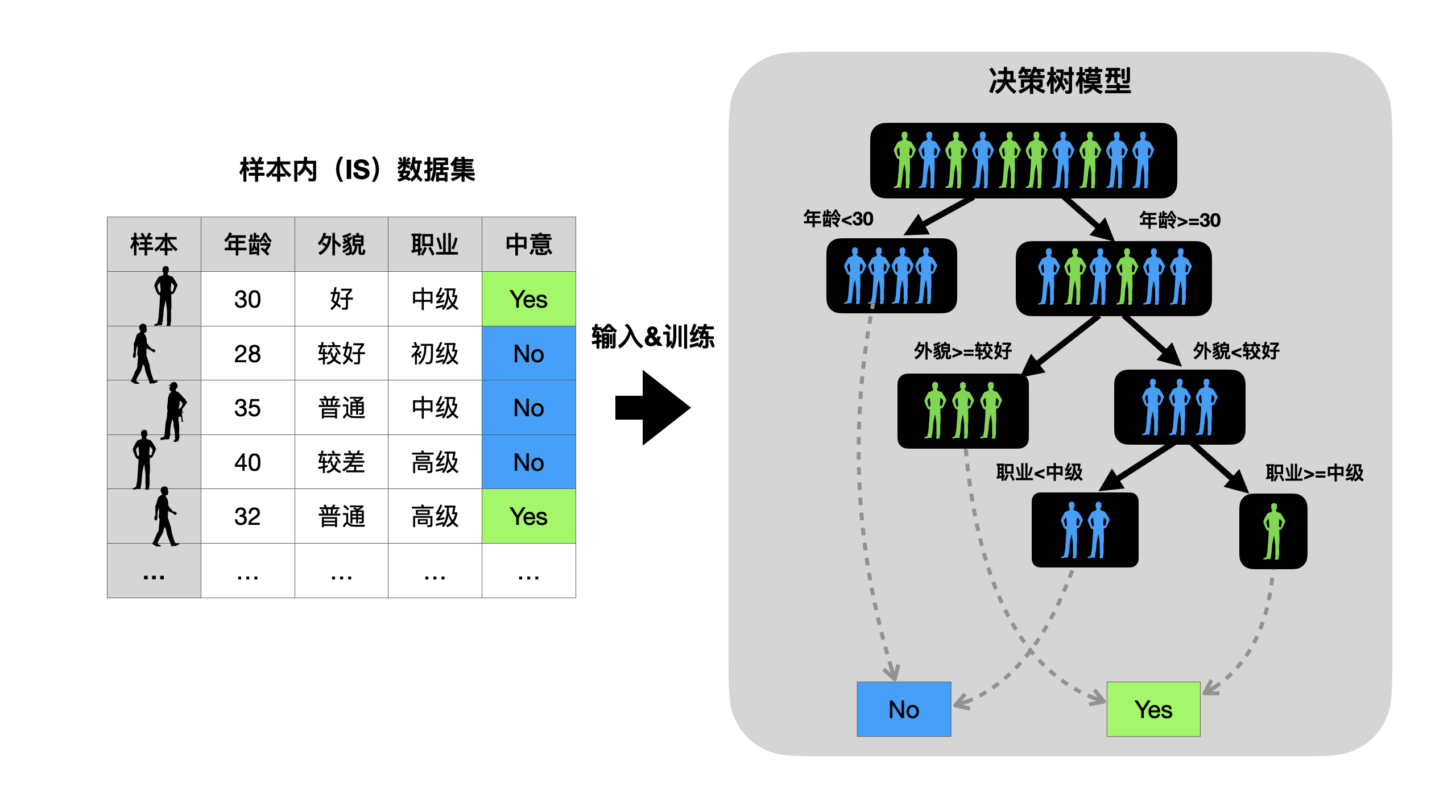
模型训练完,也就是决策树生成完毕后,就可以将样本内的数据输入到模型中。然后,观察模型预测的结果和真实的标签,两者之间的差异,这代表了模型的学习能力。
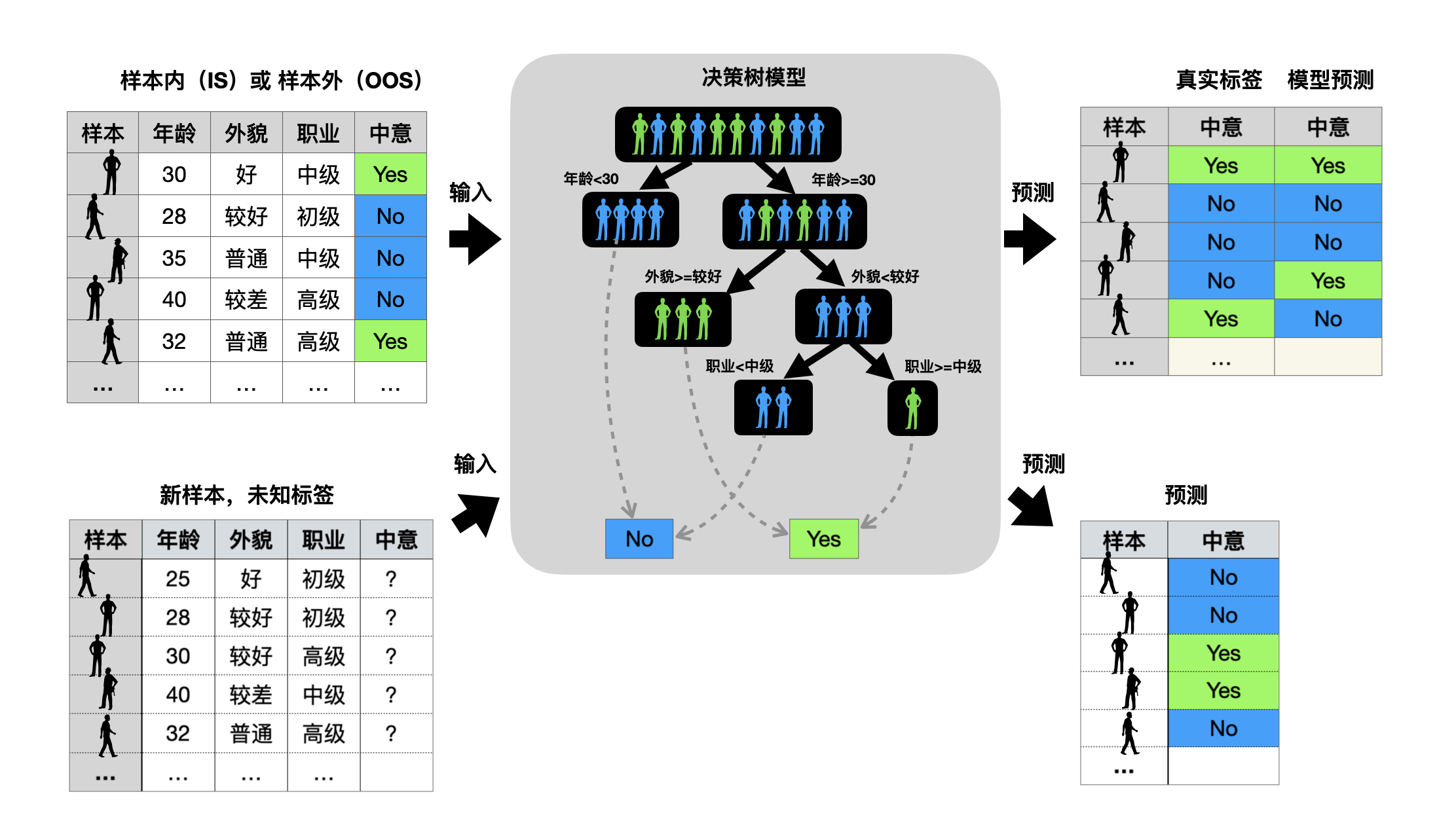
2.2 样本外(OOS)的评估以及未知样本的预测¶
在模型学习到刘小姐的偏好后,就可以在刘小姐不在线的时候,也可以帮助其筛选样本了。当输入新的未知标签的数据到模型,模型会根据已经训练后的决策树的路径,很多就可以对样本进行分类,属于“Yes”还是“No”。
3. 划分的选择¶
关于决策树从最上面的根节点,到下面的中间节点以及末端的叶节点,如何划分,换句话说在每一次划分选择哪个属性进行划分,决定了决策树的形状。
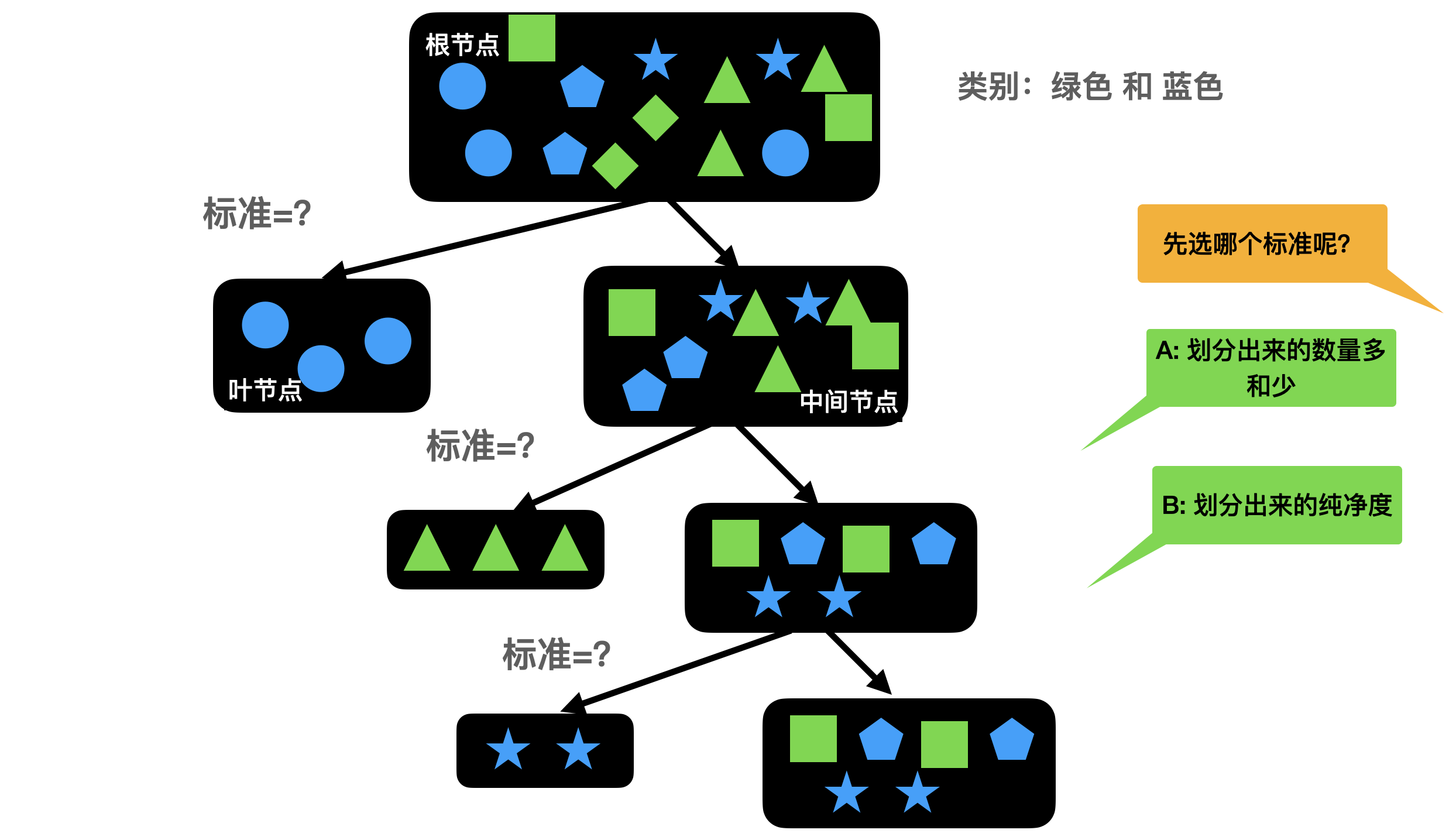
如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点“纯度”(purity)越来越高。
节点的Gini属性用于测量它的纯度:如果一个节点包含的所有训练样例全都是同一类别的,我们就说这个节点是纯的(Gini=0)。 Gini计算如下: