6.5 财经文本的获取
财经新闻数据通常涵盖了各种类别,涉及到金融市场、经济、企业、行业等方面的内容。以下是一些常见的财经新闻数据类别:
| 财经新闻数据 | 类别 | 内容 |
|---|---|---|
| 股市新闻 | 公司新闻 | 特定公司的新闻,包括业绩公告、重大事件、合并收购等。 |
| 行业新闻 | 特定行业或行业走势的新闻,包括行业分析、发展趋势等。 | |
| 市场分析 | 股票市场、债券市场、商品市场等方面的分析和预测。 | |
| 经济新闻 | 宏观经济 | 国家或地区整体经济状况、政策变化等方面的新闻。 |
| 经济数据 | 各种经济数据,如国内生产总值(GDP)、就业数据、通货膨胀率等。 | |
| 金融政策 | 中央银行政策 | 央行货币政策、利率决策等方面的新闻。 |
| 政府政策 | 财政政策、税收政策等方面的新闻。 | |
| 国际财经 | 国际金融 | 国际金融市场、外汇市场、国际贸易等方面的新闻。 |
| 全球经济 | 全球经济走势、国际经济关系等方面的新闻。 | |
| 商业新闻 | 商业动态 | 企业经营活动、商业策略、市场竞争等方面的新闻。 |
| 创业投资 | 创业公司、风险投资、创业生态等方面的新闻。 |
1. 网络爬虫¶
不管是商业数据集,还是财经数据集,很多被嵌入到网页的结构和样式中,难以复制,需要使用特殊方法抓取出来。从网页中抽取数据的过程被称为网络爬虫。
2. 客户端与服务器¶
客户端(Clients)通常是浏览器(Chrome、Edge、Safari),它们可以是任何类型的程序或设备。
服务器(Servers)最常见的是云端服务器。
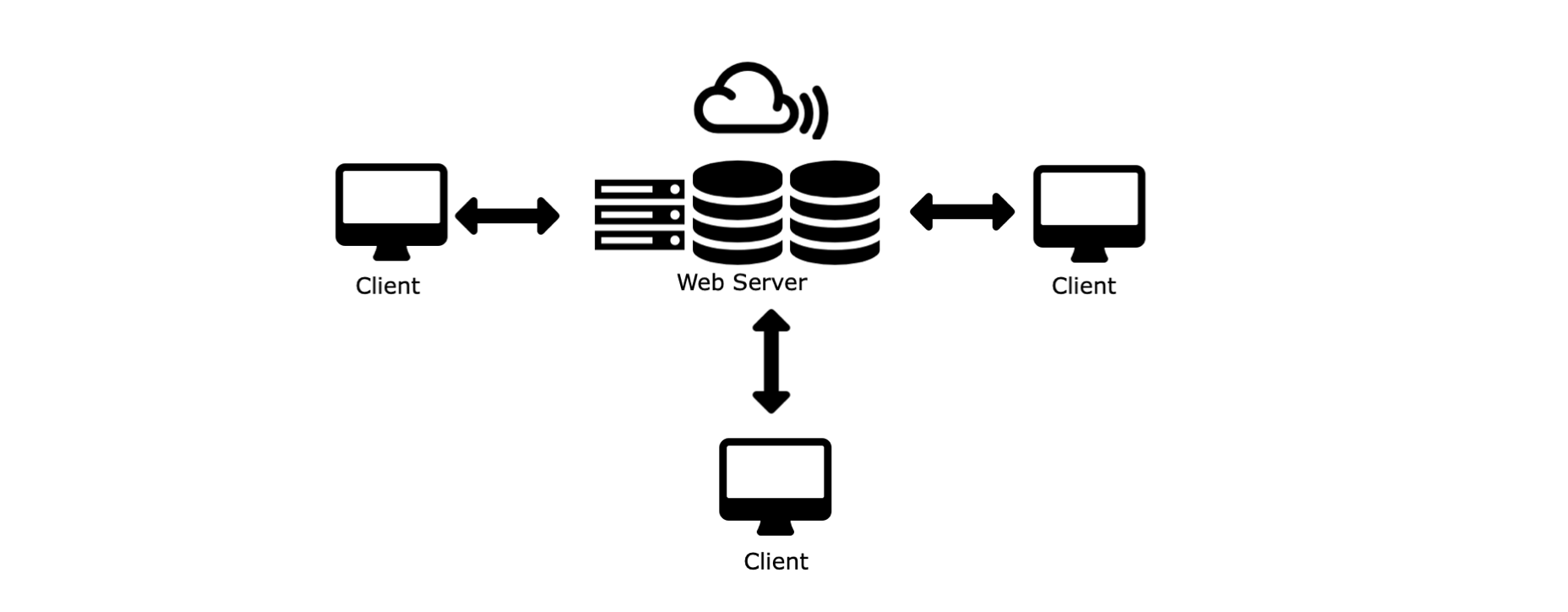
客户端(Clinet)和服务器(Server)之间的通信是通过请求(request)和响应(response)完成的:
客户端,通常是浏览器向网络发送一个HTTP请求(request)
服务器收到该请求
服务器运行一个应用程序来处理该请求
服务器向浏览器返回一个HTTP响应(response)
浏览器收到该响应
以下是一些和网络爬虫相关,你需要知道的基本概念:
| 名词 | 英文全称 | 概念解释 |
|---|---|---|
| HTTP | Hypertext Transfer Protocol | 超文本传输协议(HTTP)是互联网协议套件模型中的一个应用层协议,用于分布式、协作式、超媒体信息系统 |
| URL | Uniform Resource Locator | 它是互联网资源的地址,它包括一个协议,一个域名,有时还包括其他定位信息 |
| 认证 | Authentication | 它对访问者的身份进行验证,例如验证用户输入的密码是否正确 |
| 重定向 | URL Redirections | 它是一种网络技术,使一个网页在多个URL地址下可用 |
| Cookies | HTTP Cookies | 它是用户浏览网站时在本地存储的相关信息,包括身份信息、登录信息、购物车和历史记录等 |
3. 使用urllib库抓取网页¶
urllib作为Python的标准库,基本上涵盖了基础的网络请求功能。
urllib中,request这个模块主要负责构造和发起网络请求,并在其中加入Headers、Proxy等。它还提供了一个稍微复杂的接口来处理常见的情况--如基本认证、cookies、代理等等。
使用 urllib.request 的最简单方法如下:
from urllib import request
resp = request.urlopen('http://www.baidu.com')
content = resp.read().decode('utf-8') #根据网站对于文字的编码类型,进行解码输出content的部分,例如前1000个字符:
content[:1000]'<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#ffffff"><meta name="description" content="全球领先的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。"><link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" /><link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索" /><link rel="icon" sizes="any" mask href="//www.baidu.com/img/baidu_85beaf5496f291521eb75ba38eacbd87.svg"><link rel="dns-prefetch" href="//dss0.bdstatic.com"/><link rel="dns-prefetch" href="//dss1.bdstatic.com"/><link rel="dns-prefetch" href="//ss1.bdstatic.com"/><link rel="dns-prefetch" href="//sp0.baidu.com"/><link rel="dns-prefetch" href="//sp1.baidu.com"/><link rel="dns-prefetch" href="//sp2.baidu.com"/><link rel="apple-touch-icon-precomposed" href="https://psstatic.cdn'上述返回的内容是一个使用HTML语言编写的字符串。HTML是超文本标记语言的缩写,它是网页的标准标记语言。上述内容包含了由<>标签表示的大量HTML元素。
4. 使用requests库抓取东方财富的网页¶
requests是一个流行的爬虫工具,它在urllib3上进行封装,使得爬虫变得更加简单。
东方财富网是一家为用户提供基于互联网的财经资讯、数据等服务,旗下拥有财经门户“东方财富网”、互联网基金销售平台“天天基金”、中国人气股票基金交流社区“股吧”等。
为了方便下一章节文本分析需要使用的数据,我们访问股票社区网站,例如股吧:http://
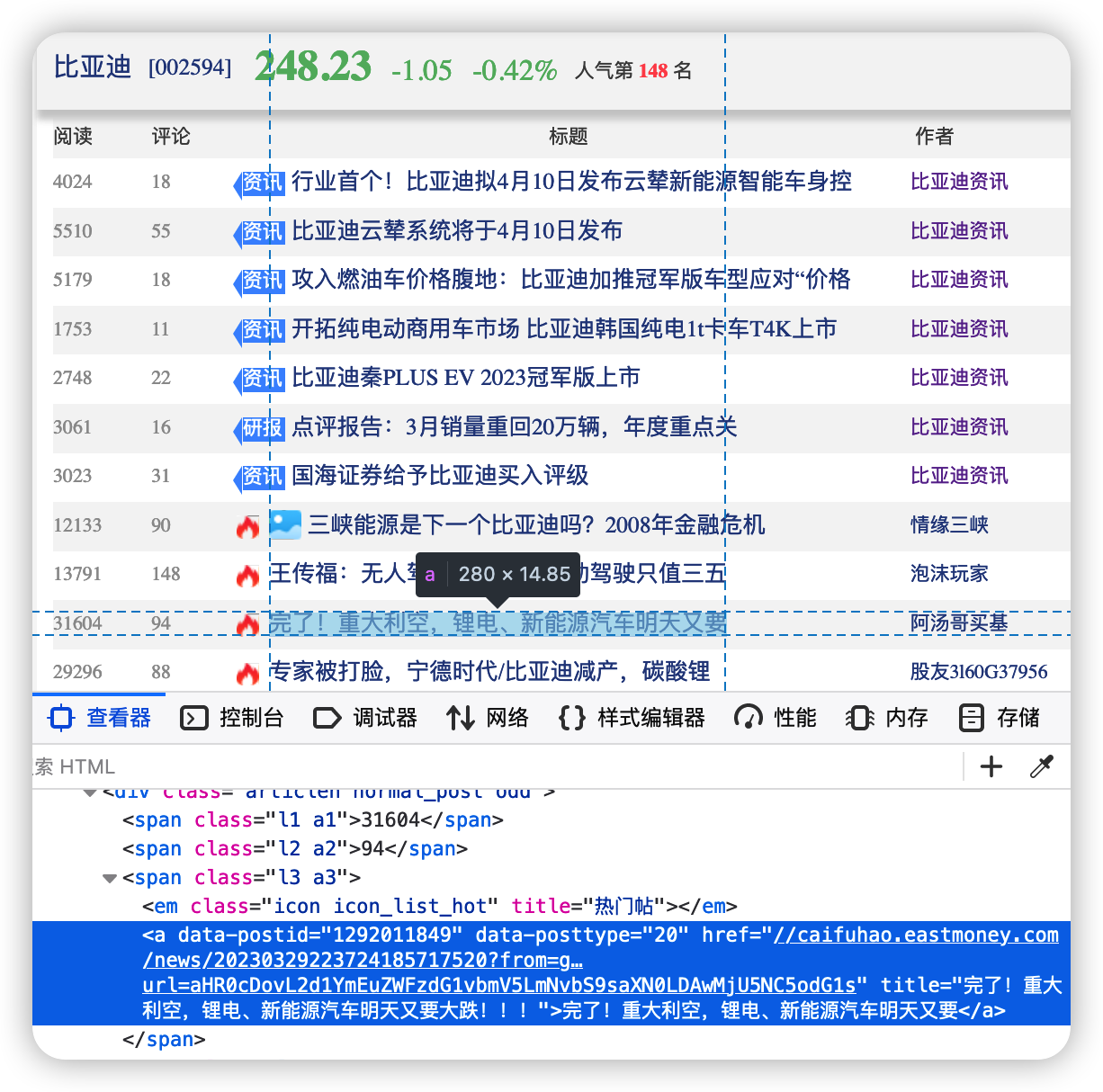
第一步,使用requests.get()函数获取html文件
import requests
headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:91.0) Gecko/20100101 Firefox/91.0"}
url = 'http://guba.eastmoney.com/list,002594.html'
req = requests.get(url=url, headers=headers)
html_doc = req.content.decode("utf-8")第二步,我们解析图片里面这句话
上图的“完了!重大利空,锂电、新能源汽车明天又要”在html的XPath路径为“/html/body/div[6]/div[2]/div[4]/div[11]/span[3]/a”。
lxml是处理XML和HTML的Python库。使用方法见官网。
from lxml import etree
html_obj = etree.HTML(html_doc)
reads_path = '/html/body/div[6]/div[2]/div[4]/div[11]/span[3]/a'
html_obj.xpath(reads_path)[0].text'完了!重大利空,锂电、新能源汽车明天又要'第三步,我们设计一个函数,用来解析html文件里面的元素
提取每一条评论的信息,包含阅读数、评论、标题、作者、最后更新时间等。
from lxml import etree
def parse_html(url, html_doc):
"""
解析html获取数据
"""
print("parse_html ...")
html_obj = etree.HTML(html_doc)
article_dict = {}
i= 2
while True:
try:
reads_path = '/html/body/div[6]/div[2]/div[4]/div[%s]/span[1]' %i
reads = html_obj.xpath(reads_path)[0].text
comments_path = '/html/body/div[6]/div[2]/div[4]/div[%s]/span[2]' %i
comments = html_obj.xpath(comments_path)[0].text
post_path = '/html/body/div[6]/div[2]/div[4]/div[%s]/span[3]/a' %i
post_href = html_obj.xpath(post_path)[0].get("href")
post = html_obj.xpath(post_path)[0].get("title")
writer_path = '/html/body/div[6]/div[2]/div[4]/div[%s]/span[4]/a/font' %i
writer = html_obj.xpath(writer_path)[0].text
update_path = '/html/body/div[6]/div[2]/div[4]/div[%s]/span[5]' %i
update = html_obj.xpath(update_path)[0].text
article_dict[i-1] = {"reads":reads,
"comments":comments,
"post":post,
"writer":writer,
"update":update}
i += 1
except IndexError:
break
return article_dictp = parse_html(url, html_doc)parse_html ...
import pandas as pd
pd.DataFrame(p).T练习¶
使用lxml.etree模块和其解析xpath()方法,访问股吧网页:http://
5. 以文件流的形式存取数据¶
with open("datasets/财经新闻示例.txt", "rb") as f:
for i in f:
print(i.decode("utf-8"))据21世纪经济报道(21财经)4日报道,9月3日,在2021中国服贸会“服务贸易开放发展新趋势高峰论坛”上,海关总署研究中心主任万中心预计,今年中国货物贸易有望实现两位数增长,达到5.1万亿美元,这意味着在“十四五”开局第一年,中国有望提前完成货物贸易的“十四五”目标。
万中心指出,疫情以来直到今天,中国货物贸易一直保持着不错的增长。根据其团队的预测,如果不出现极端情况的话,今年中国货物贸易进出口会实现两位数的增长,“这个两位数的增长不仅仅是针对去年的同比增速,相较于疫情前的2019年,今年也有望实现年均两位数的增长,接近‘十一五’时期的数字。”
他指出,按此测算,中国货物贸易的国际市场份额将进一步提升至15%左右。
值得注意的是,根据此前公布的《“十四五”商务发展规划》,“十四五”期间,中国的货物贸易的预期目标为:到2025年,中国货物贸易规模达到5.1万亿美元。“今年,中国有可能达到5.1万亿美元,大概率在今年,也就是‘十四五’开局第一年提前完成这一目标。”
万中心指出,中国货物贸易在“十二五”、“十三五”期间的年均增速分别为7.6%、2.6%,《“十四五”商务发展规划》的预期目标是,“十四五”期间年均增长2%。
在这个示例中,我们首先导入了requests库和Beautiful Soup库,然后定义了要抓取的新闻网站的URL(这里以CNBC财经新闻为例)。接着,我们使用requests库发起了HTTP请求,并通过Beautiful Soup库解析了网页内容。我们通过查找特定的HTML元素来提取新闻标题,并将其打印输出。
参考¶
Cookies: https://
www .kaspersky .com /resource -center /definitions /cookies urllib官方文档: https://
docs .python .org /3 /library /urllib .request .html# HOWTO Fetch Internet Resources Using The urllib Package:https://
docs .python .org /3 /howto /urllib2 .html #urllib -howto